


Introduction: Revolutionizing AI Communication
In this inaugural post of our series, we dive into the transformative world of Transformer models, the architecture reshaping artificial intelligence's approach to understanding language. From the foundational concept of Word Embeddings, which introduced us to vector representations of language, we now step into the realm where Transformers address their predecessors' limitations.


The Advent of Transformers
Transformers, introduced by Vaswani et al. in the landmark paper "Attention is All You Need" in 2017, have become synonymous with state-of-the-art NLP. Central to their innovation is the self-attention mechanism, allowing models to contextually weigh the importance of words within a sentence. This not only enhances understanding of language nuances but does so with unprecedented efficiency by processing data in parallel.
A Universal Architecture
Initially breaking ground in NLP, the versatility of Transformer models quickly extended their application across various AI domains, from computer vision to protein structure prediction. Their ability to generalize from large datasets through pre-training, followed by task-specific fine-tuning, has set new standards in AI performance.
Our series will explore the intricate details of Transformer models, including their architecture, the pivotal self-attention mechanism, and their profound impact across AI tasks. We aim to bridge the conceptual with the practical, providing insights into implementing these models for your projects.
Join us as we embark on a journey through the architecture that has become the backbone of modern AI, understanding how Transformers not only enhance machine understanding of language but also pave the way for future innovations in the field.
Understanding the Transformer Architecture
The Transformer architecture marks a departure from previous sequence processing models that relied heavily on recurrent (RNN) or convolutional neural networks (CNN). By introducing the self-attention mechanism, Transformers offer a more efficient and flexible way to handle sequential data, especially language.
Core Principles
Self-Attention: The heart of the Transformer model is its ability to process all parts of the input data simultaneously, as opposed to sequentially. Self-attention allows each word in a sentence to be compared to every other word, determining how much focus it should give to other parts of the sentence as it processes each word. This mechanism is key to understanding the contextual relationship between words in a sentence.
Parallel Processing: Unlike models that process data points sequentially (like RNNs), Transformers handle entire sequences at once. This parallel processing significantly speeds up training and inference times, making it feasible to work with large datasets and complex models.
Transformer Model Architecture
The Transformer model is divided into two main parts: the encoder and the decoder. Each part is composed of a stack of identical layers that have two main sub-layers: a multi-head self-attention mechanism and a fully connected feed-forward network.

Encoder: The encoder's role is to process the input data and encode it into a context-rich representation. Each encoder layer begins with a multi-head self-attention mechanism, followed by normalization and a simple, position-wise fully connected feed-forward network. The output of each encoder is passed to the next layer as input, with the final encoder output serving as the input for the decoder.
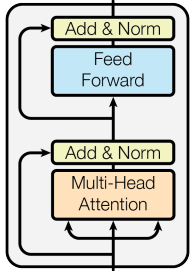
Decoder: The decoder takes the encoder's output and generates the final output sequence. It is also made up of multiple layers that contain the components of the encoder plus an additional multi-head attention layer that focuses on the encoder's output. This structure allows the decoder to focus on relevant parts of the input sequence during the generation process, facilitating accurate translation or text generation.

Positional Encoding: Since Transformers do not process data sequentially, they use positional encodings to consider the order of the sequence. These encodings are added to the input embeddings at the bottoms of the encoder and decoder stacks, providing information about the position of each word in the sequence.
Why It Matters
The Transformer's architecture enables more than just efficiency; it allows for a more nuanced understanding of language. By evaluating all parts of the input simultaneously, Transformers can capture complex dependencies and contextual nuances that were difficult or impossible for earlier models. This capability has led to significant improvements in a wide range of NLP tasks, from machine translation to text summarization and question answering.
The Transformer's introduction has not only revolutionized NLP but also served as a foundation for developing models that learn from vast amounts of data across multiple tasks, pushing the boundaries of what AI systems can achieve. Its architecture has inspired a wave of innovations, including models like BERT for understanding context in language and GPT for generating human-like text, highlighting its versatility and impact across the AI landscape.
From Theory to Application
The theoretical underpinnings of the Transformer architecture have propelled it beyond academic interest, making a profound impact on practical applications across various domains of artificial intelligence. This section explores how the theory of Transformers translates into real-world applications, emphasizing their versatility and the broad scope of tasks they have revolutionized.
NLP: The Primary Battlefield
Transformers first made their mark in natural language processing (NLP), where they addressed some of the most challenging tasks with unprecedented success:
Machine Translation: The ability of Transformers to process entire sentences at once, understanding the context of each word in relation to all others, significantly improved machine translation. This improvement is not just in the quality of translation but also in the model's ability to handle languages with varying syntax and structure smoothly.
Text Summarization: Summarizing long documents into concise, informative abstracts requires a deep understanding of the text. Transformers achieve this by capturing nuances and determining which parts of the text are most relevant to the summary.
Question Answering: By understanding the context of both the question and the provided text, Transformer-based models can pinpoint the most accurate answers, demonstrating a deep comprehension of the material.
Extending Beyond NLP
The versatility of the Transformer architecture has allowed its principles to be adapted for tasks outside traditional NLP:
Computer Vision: Vision Transformers (ViT) apply the self-attention mechanism to sequences of image patches, enabling the model to recognize patterns and details across the entire image. This approach has shown promising results in tasks like image classification, object detection, and more, challenging the dominance of convolutional neural networks in the field.
Speech Recognition: Transformers have been applied to speech recognition, where they process audio signals to transcribe spoken language into text. Their ability to capture long-range dependencies in audio data makes them particularly effective for this application.
Protein Structure Prediction: In the field of bioinformatics, Transformer models have been used to predict the 3D structures of proteins based on their amino acid sequences. This application showcases the model's ability to understand complex, sequential relationships in data beyond language.
Generative Pre-trained Transformers, notably GPT-3 and GPT-4, represent a pinnacle in the evolution of Transformer models, specializing in generating human-like text. Unlike the original Transformer architecture, which utilizes both an encoder and a decoder for tasks like translation, GPT models streamline the process by employing only the decoder component. This design choice is pivotal for their generative capabilities. The decoder's architecture, optimized for predicting the next word in a sequence given all the previous words, makes it inherently suited for text generation tasks. By focusing on the decoder, GPT models leverage the self-attention mechanism to understand and generate text based on the vast amounts of information they've been pre-trained on. This approach allows them to produce coherent and contextually relevant text across a wide range of topics and styles, setting new standards for AI's creative and linguistic abilities. We'll cover the intricacies of Generative Pre-trained Transformers and their applications in future posts, unpacking how they continue to redefine the boundaries of machine-generated content.
The Significance of Pre-training and Fine-tuning
The advent of the Transformer architecture has ushered in a new era of model development in artificial intelligence, particularly through its innovative approach to learning: pre-training and fine-tuning. This methodology has proven crucial in harnessing the full potential of Transformer models across various domains, fundamentally changing the landscape of machine learning.
Pre-training: Laying the Foundation
Pre-training involves training a Transformer model on a large, diverse dataset before it is fine-tuned for specific tasks. This phase allows the model to learn a wide range of language features and structures, essentially understanding the "language of the world" it is going to operate in. For NLP tasks, this means absorbing grammar, syntax, and even some level of world knowledge from the text. In other domains, such as computer vision or bioinformatics, pre-training helps the model grasp fundamental patterns and relationships within the data.
The benefits of pre-training are manifold:
Generalization: By learning from a broad dataset, the model develops a generalized understanding, making it adaptable to a wide variety of tasks.
Efficiency: Once pre-trained, the same model can be fine-tuned for multiple tasks, reducing the need for training from scratch for each new application.
Performance: Pre-trained models often achieve state-of-the-art performance, even with relatively small amounts of task-specific data during fine-tuning.
Fine-tuning: Tailoring to Tasks
Fine-tuning adjusts a pre-trained model to a specific task by continuing the training process on a smaller, task-specific dataset. This phase allows the model to adapt its generalized knowledge to the nuances and specific requirements of the target task. For example, a model pre-trained on a large corpus of English text can be fine-tuned to perform sentiment analysis on product reviews or legal document summarization.
Key aspects of fine-tuning include:
Customization: Fine-tuning allows for the customization of the model to specific domains or tasks, enhancing its relevance and accuracy.
Reduced Data Requirement: Because the model has already learned a significant amount of information during pre-training, fine-tuning requires much less labeled data than training a model from scratch.
Quick Adaptation: The fine-tuning process is typically much faster than the initial pre-training, enabling rapid deployment of customized models.
The Synergy Between Pre-training and Fine-tuning
The combination of pre-training and fine-tuning leverages the strengths of both approaches: the broad, general understanding gained from pre-training and the specific, task-oriented focus of fine-tuning. This synergy allows Transformer models to achieve exceptional performance across a wide range of tasks, from general language understanding in models like BERT to creative content generation in models like GPT.
Moreover, the pre-training and fine-tuning paradigm has democratized access to powerful AI tools. With the availability of pre-trained models through libraries like Hugging Face's Transformers, developers and researchers can now fine-tune cutting-edge models for their specific needs without the prohibitive costs and computational resources required for training large models from scratch.
In essence, the significance of pre-training and fine-tuning in the Transformer model development process cannot be overstated. This approach has not only propelled Transformers to the forefront of AI research and application but also set a new standard for developing and deploying machine learning models across industries.
Conclusion
As we wrap up the first week of our deep dive into the fascinating world of Transformer models, we've laid the groundwork for understanding their revolutionary impact on artificial intelligence. From redefining natural language processing tasks with their innovative self-attention mechanism to broadening their application across various domains, Transformers have established themselves as a cornerstone of modern AI.
The dual process of pre-training and fine-tuning has emerged as a pivotal strategy, enabling these models to achieve remarkable versatility and performance. This approach not only enhances the models' efficiency and adaptability but also democratizes advanced AI capabilities, making state-of-the-art models accessible for fine-tuning to specific tasks with relatively minimal effort.
As we move forward in this series, we will go deeper into the specifics of the Transformer architecture, explore its most influential implementations, and guide you through practical applications. Our journey has just begun, and the potential for innovation and discovery within the realm of Transformers remains vast and largely untapped.
Join us next week as we continue to explore self-attention, the backbone of the Transformer's success, and how it enables these models to understand and generate language with an unprecedented level of sophistication.
References:
Vaswani, et al. Attention Is All You Need, 2017. https://doi.org/10.48550/arXiv.1706.03762
Dosovitskiy, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, 2021. https://doi.org/10.48550/arXiv.2010.11929