
The Power of Words in AI, Part I
An Introduction to Word Embeddings


Introduction
In the evolving landscape of artificial intelligence (AI) and natural language processing (NLP), the way we understand and process human language has undergone a transformative shift. At the heart of this revolution lies a seemingly simple, yet profoundly impactful concept: word embeddings. This post marks the beginning of our journey into the intricate world of word embeddings, a journey that not only underscores the power of words in AI but also paves the way for the sophisticated language models we'll explore in the coming weeks, including the mighty transformers.
From One-Hot Encoding to Embeddings: A Paradigm Shift
Rewind a few years, and the landscape of NLP was markedly different. Traditional methods of text representation, like one-hot encoding, dominated the scene. While straightforward, these methods had a significant drawback: they failed to capture the nuanced meanings and relationships between words. Imagine trying to understand a language by merely acknowledging whether a word exists in a sentence, without grasping its context, connotations, or its relationship with other words. This approach, akin to trying to appreciate a symphony by only recognizing the presence of notes without understanding the melody, was the fundamental limitation of early text representation techniques.
Enter word embeddings. This innovative approach to word representation heralded a new era in NLP. Unlike their predecessors, word embeddings don't treat words as isolated entities. Instead, they represent each word as a vector in a continuous, multidimensional space. This enables them to capture and quantify the semantic relationships between words, a feat that was once considered elusive in the realm of computational linguistics.
In this post, we will unfold the layers of word embeddings. We'll start by defining what they are and why they represent a leap forward in NLP. We'll then cover the early methods that gave way for embeddings and discuss two pivotal models: Word2Vec and GloVe. These models not only shaped the future of word embeddings but also laid the groundwork for more advanced language processing tools, which we'll explore in subsequent posts.
Basics of Word Embeddings
What are Word Embeddings?
At its core, a word embedding is a technique used in NLP where words or phrases from the vocabulary are mapped to vectors of real numbers. This concept may sound abstract, but it's akin to translating the essence of words into a language that computers understand. In traditional computational linguistics, words were often represented as unique, one-dimensional points in a large, sparse space (one-hot encoding). However, this method was severely limited, as it couldn't capture the nuances of language, such as context or the relationship between words.
Word embeddings revolutionize this approach by representing words in a continuous vector space where semantically similar words are mapped to points close to each other. This transformation is typically achieved through sophisticated neural network models that are trained on large text corpora. These neural networks learn to produce these embeddings by processing vast amounts of text, enabling the models to understand word usage and meaning based on the context in which words appear. Through this training process, the neural networks effectively encode each word into a more informative, multi-dimensional vector, often with hundreds of dimensions.
The use of neural networks in creating word embeddings marks a significant advancement in NLP. It allows for a more dynamic and context-aware representation of language, capturing subtle semantic relationships and patterns that were previously elusive with simpler models.

Importance of Semantic Meaning
The real power of word embeddings lies in their ability to capture semantic meaning. In the multi-dimensional space, the 'distance' and 'direction' between vectors can represent relationships between words. For instance, in a well-trained model, vectors for words like 'king' and 'queen' might be close together, indicating their related meanings. This proximity is not just about synonyms; it's about capturing a wide array of semantic relationships, including opposites, items and their categories, and so forth.
Moreover, word embeddings can capture complex patterns that go beyond mere word pairs. For example, they can understand analogies: the famous example being "king - man + woman = queen." This is possible because the relationships between words are encoded as directions in the embedding space, a feat unachievable with older methods.
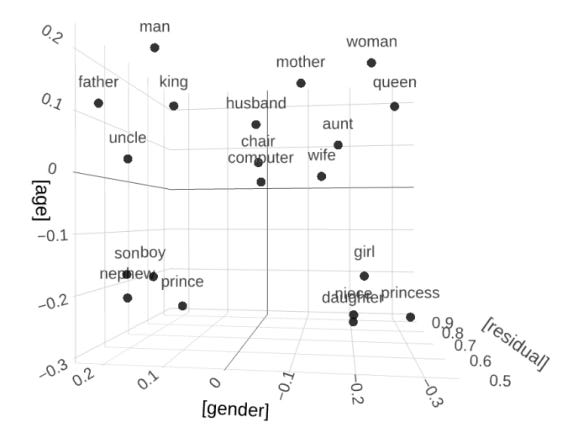
Understanding Dimensionality
The dimensionality of a word embedding is a crucial aspect to consider. Each dimension represents a latent feature of the word, often not interpretable by humans. While higher dimensionality can capture more information, it also means more computational complexity and potential overfitting. On the other hand, too few dimensions might not capture enough semantic information. Therefore, choosing the right dimensionality is a balance between computational efficiency and the richness of the semantic information captured. Typically, word embeddings are several hundred dimensions.
In this section, we have introduced the fundamental concepts of word embeddings. We have seen how they represent a significant advancement over previous methods of word representation, primarily through their ability to capture the rich semantic relationships inherent in language. As we move deeper into the different types of word embeddings and their applications in subsequent sections, we'll gain a fuller appreciation of their power and utility in NLP.
Evolution of Word Embeddings
The journey of word embeddings in natural language processing (NLP) is a fascinating evolution, from simplistic beginnings to complex and nuanced representations. This section covers this progression, highlighting key milestones that have significantly impacted the field.
Early Methods: Count-Based Approaches
The initial attempts at creating word embeddings were rooted in count-based methods. Techniques like Term Frequency-Inverse Document Frequency (TF-IDF) and co-occurrence matrices laid the foundation. In these methods, the focus was on how frequently a word appears in a document or alongside other words, respectively. While these approaches did provide some basic insights into word usage, they were limited in their ability to capture deeper semantic meanings. The primary limitation was their focus on raw frequency counts, leading to high-dimensional, sparse vectors that were inefficient and lacked the ability to represent word context effectively.
Word2Vec: A Leap Forward
The introduction of Word2Vec by researchers at Google marked a significant shift in the development of word embeddings. Word2Vec is a predictive model that learns word embeddings from raw text using a shallow neural network. It comes in two flavors:
Skip-Gram Model: This model predicts the context (surrounding words) given a target word. It's particularly effective for learning high-quality representations of infrequent words.

Continuous Bag of Words (CBOW): Contrary to Skip-Gram, CBOW predicts a target word based on its context. It's faster and tends to perform better with frequent words.
Word2Vec's key innovation was its ability to capture semantic relationships in a low-dimensional space, making the representations denser and more meaningful than its count-based predecessors. The embeddings created by Word2Vec encode much more information about a word's meaning, including syntactic and semantic information, based on the contexts in which a word appears.
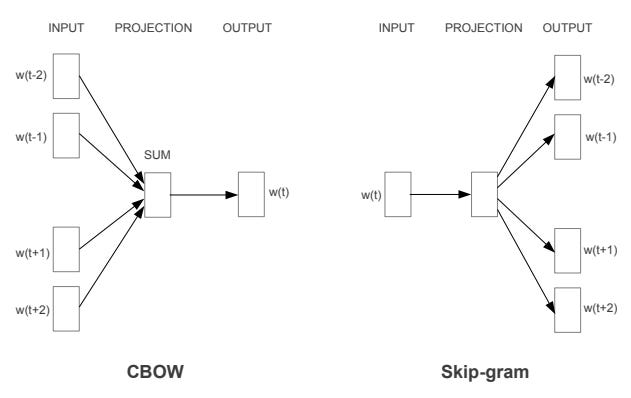
GloVe: Bridging the Gap
Global Vectors for Word Representation, or GloVe, developed by Stanford University, is another pivotal development in word embeddings. GloVe combines the benefits of both count-based and predictive models. It does this by constructing a co-occurrence matrix and then applying matrix factorization techniques, essentially capturing global corpus statistics. GloVe excels in capturing subtler relationships by looking at the overall statistics of the word co-occurrences, thereby addressing some of the limitations of Word2Vec, which relies heavily on local context information.
The advancements brought by Word2Vec and GloVe marked a significant leap in the evolution of word embeddings. They shifted the focus from mere occurrence counts to understanding the contextual relationships between words, leading to more nuanced and sophisticated representations. This evolution paved the way for even more advanced language models, incorporating contextual nuances at a level previously unattainable, setting the stage for the next leap in NLP: contextual embeddings, which we will explore in our subsequent posts.
Conclusion
We've journeyed through the evolution of word embeddings, a cornerstone in NLP. From the basic count-based methods to the nuanced Word2Vec and GloVe models, we've seen how word embeddings have revolutionized the way machines understand human language. These developments have not only enhanced semantic representation but also laid the groundwork for more complex language models.
Preview of Next Week
Next week, we'll cover the world of contextual embeddings. We'll explore ELMo (Embeddings from Language Models), which represents a significant advancement over traditional embeddings by capturing the full context of word usage. This exploration will serve as a bridge to understanding transformers, showcasing how contextual understanding in NLP has evolved. We'll also touch on the applications and challenges of these advanced embeddings, setting the stage for a comprehensive look at the transformative impact they have on NLP tasks.
Thank you for reading!
References:
Mikolov, et al. “Efficient Estimation of Word Representations in Vector Space.” . https://arxiv.org/pdf/1301.3781.pdf (2013).
Almeida, Felipe, and Geraldo Xexéo. "Word embeddings: A survey." arXiv preprint arXiv:1901.09069 (2019).
Kis