
The Power of Words in AI, Part II
Advancing into Contextual Word Embeddings


Introduction
Welcome back to our exploration of the fascinating world of word embeddings in natural language processing (NLP). Last week, we journeyed through the basics of word embeddings, unraveling how they transform words into meaningful vectors. We covered foundational models like Word2Vec and GloVe, which revolutionized how machines understand human language. But that was just the beginning.

This week, we're going to dive deeper. The realm of word embeddings is vast and continuously evolving, and here, we stand at the threshold of some of the most advanced and intriguing concepts in this field. The need for context and nuance in language understanding leads us to 'Contextual Word Embeddings.' Models like ELMo marked a significant leap forward, paving the way for even more sophisticated architectures like transformers, which we will explore in subsequent posts.
As we embark on this week's journey, remember that the field of NLP is as dynamic as it is exciting. What we discuss here is at the forefront of bridging the gap between human language and machine understanding. So, let's dive in and discover the advanced landscapes of word embeddings and their pivotal role in modern AI.
Contextual Word Embeddings
The evolution of word embeddings took a significant leap forward with the advent of contextual word embeddings. Unlike traditional embeddings, which assign a fixed vector to each word, contextual embeddings dynamically generate word representations based on the surrounding text. This approach allows the model to capture nuances, polysemy, and the complex dynamics of language usage.
The Concept of Context in Language Processing
Traditional vs. Contextual Embeddings: Traditional embeddings like Word2Vec and GloVe generate a single embedding for each word, regardless of its context. This leads to a significant limitation: the inability to represent words with multiple meanings (polysemy) effectively. In contrast, contextual embeddings adjust the representation of a word based on its context, providing a more nuanced and accurate understanding of its use in different scenarios.
Example of Polysemy: Take the word "bank." In "river bank," it has a completely different meaning than in "savings bank." Contextual embeddings can distinguish these meanings based on surrounding words, a task impossible for traditional embeddings.
ELMo: The Pioneer of Contextual Embeddings
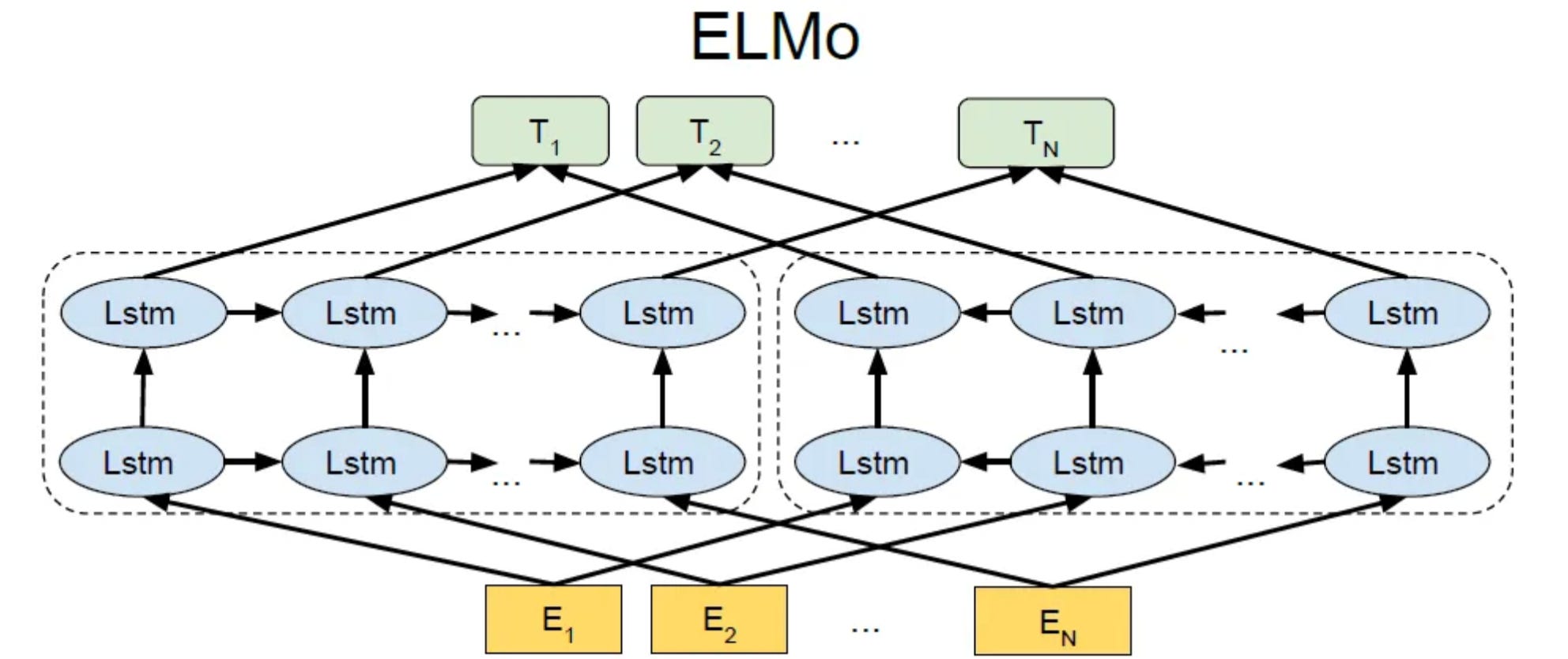
Introduction to ELMo: ELMo (Embeddings from Language Models) represents a significant shift in the word embedding paradigm. Developed by researchers at the Allen Institute for AI, ELMo was one of the first models to generate context-dependent word embeddings.
How ELMo Works: ELMo uses a bidirectional LSTM (Long Short-Term Memory) trained on a language modeling task. It produces embeddings by considering the entire sentence to capture context, and as a result, the same word can have different embeddings based on its usage in different sentences.
Benefits over Traditional Embeddings: By considering context, ELMo addresses the limitations of polysemy and improves performance across a range of NLP tasks, including sentiment analysis, named entity recognition, and question answering.
Beyond ELMo: Advancements in Contextual Embeddings
BERT and Transformers: Following ELMo, models like BERT (Bidirectional Encoder Representations from Transformers) introduced the transformer architecture, further revolutionizing the approach to contextual embeddings. Unlike ELMo's LSTM-based approach, BERT leverages the transformer's attention mechanism, offering even more nuanced and efficient contextual understanding.
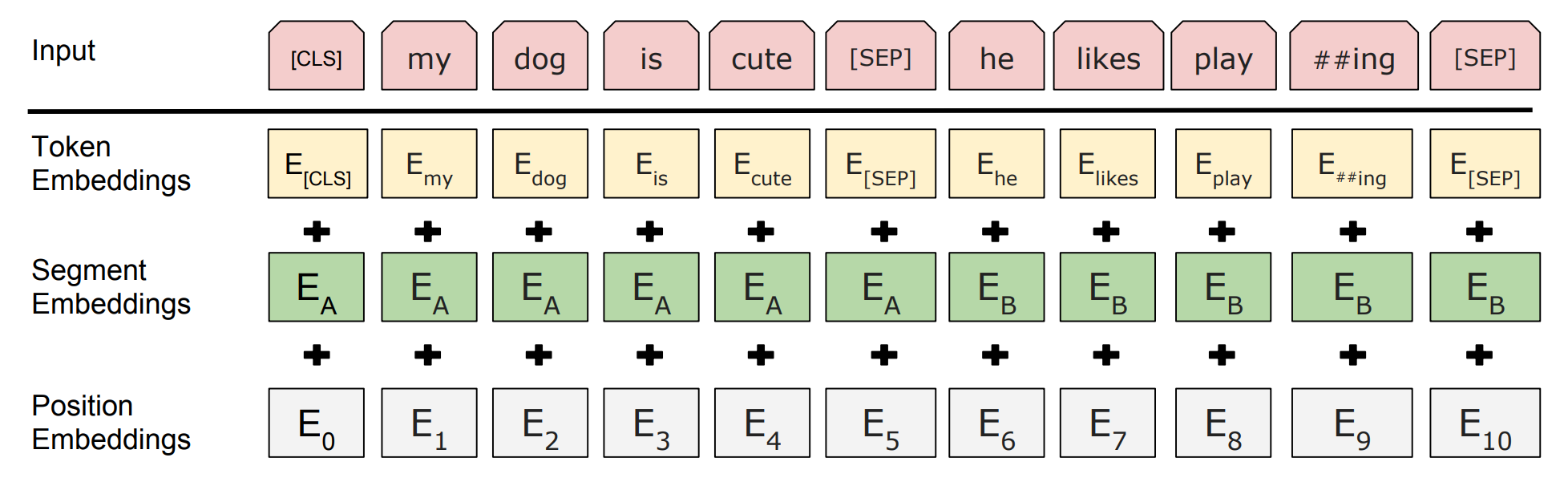
Advantages of Transformer-Based Models: These models can process words in relation to all other words in a sentence, rather than sequentially. This allows for a more profound and comprehensive understanding of context.

Challenges and Considerations
Computational Intensity: Generating contextual embeddings is computationally more demanding than traditional embeddings. Models like BERT require significant computational resources for training, making them less accessible for small-scale applications or teams with limited resources.
Handling Longer Dependencies: While models like ELMo and BERT provide better context understanding, they sometimes struggle with very long texts where dependencies may span beyond the model's immediate context window.
In this section, we've seen how contextual word embeddings mark a substantial advancement in the field of NLP, offering a more dynamic and accurate representation of language. As we move towards models that better capture the intricacies of human language, the potential applications and impacts of these technologies in various domains continue to expand. This progress sets the stage for exploring the transformative power of transformer models, which we will cover in our upcoming posts.
Practical Applications and Challenges
The advancement in word embeddings, particularly contextual embeddings, has not only reshaped our understanding of language processing in AI but also opened up a plethora of practical applications. However, these innovations come with their own set of challenges. Let's delve into how these advancements are being applied and the hurdles they face in real-world scenarios.
Wide-Ranging Applications of Contextual Embeddings
Enhanced NLP Tasks: Contextual embeddings have significantly improved performance in various NLP tasks. For instance, in sentiment analysis, these embeddings provide a deeper understanding of the context, leading to more accurate detection of sentiment nuances. In named entity recognition, they help distinguish between entities based on context, improving accuracy.
Machine Translation: The ability to understand context has greatly improved machine translation. Contextual embeddings can capture the subtleties of language, resulting in translations that are not just grammatically correct but also contextually appropriate.
Personalized Chatbots and Virtual Assistants: With the advent of contextual embeddings, chatbots and virtual assistants have become more sophisticated. They are now better equipped to understand the context of a conversation, making their responses more relevant and human-like.
Content Recommendations: In the realm of content recommendation, such as news feeds or streaming services, these embeddings can analyze user preferences with greater accuracy and recommend content that aligns more closely with individual tastes.
Challenges and Ethical Considerations
Computational Demands: One of the primary challenges with contextual embeddings, especially models like BERT, is their computational intensity. Training these models requires significant computational power and large datasets, making them resource-intensive.
Bias in Language Models: A critical issue in NLP is the inherent bias in language models. Contextual embeddings, derived from large datasets, can inadvertently learn and perpetuate societal biases present in the training data. Addressing these biases is crucial for ethical AI practices.
Out-of-Vocabulary (OOV) Words: Despite advancements, handling OOV words remains a challenge. While embeddings can infer meanings based on context, the effectiveness diminishes with the rarity of the word or its absence in the training data.
Data Privacy and Security: As these models often require extensive data, there are concerns regarding data privacy and security. Ensuring that personal data is not compromised while training and deploying these models is paramount.
Interpretability and Explainability: With the increasing complexity of models, understanding how they make decisions (model interpretability) becomes challenging. This is particularly important in high-stakes applications like healthcare or finance, where explainability is essential.
While contextual embeddings have significantly advanced the field of NLP, introducing more nuanced and effective language understanding, they also present challenges that need addressing. From computational demands and data biases to privacy concerns and the need for model interpretability, these challenges highlight the importance of ongoing research and development in the field. As we continue to harness the power of AI in language processing, addressing these issues is key to realizing the full potential of these technologies in practical applications.
Working with Word Embeddings
Working with word embeddings, particularly in a PyTorch environment, involves understanding how to integrate these rich language representations into your models. In this section, we'll explore how to utilize pre-trained embeddings and then delve into the practicalities of using embeddings in PyTorch, including an example to illustrate the process.
Utilizing Pre-trained Embeddings
Pre-trained word embeddings are a powerful tool, allowing you to leverage large-scale language models without the computational cost of training them from scratch. Libraries like Gensim offer easy access to pre-trained models such as Word2Vec, GloVe, and FastText. These can be directly loaded into your application and used to transform text data into meaningful vector representations.
Word Embeddings in PyTorch
PyTorch provides a convenient way to work with these embeddings, whether they are pre-trained or custom-trained. Below is an example of how to use pre-trained embeddings in PyTorch:
Loading Pre-trained Embeddings: Let's assume you have GloVe embeddings downloaded. You can load these into PyTorch using the
torchtextlibrary which contains utilities for working with text data.Embedding Layer in PyTorch: The
nn.Embeddinglayer in PyTorch is designed to handle embeddings. It takes two main arguments: the size of the dictionary (number of embeddings) and the size of each embedding vector.
Here's a simple example of how to use an embedding layer in PyTorch:
import torch
import torch.nn as nn
from torchtext.vocab import GloVe
# Load pre-trained GloVe embeddings
glove = GloVe(name='6B', dim=100)
# A simple model with an embedding layer
class SimpleModel(nn.Module):
def __init__(self, vocab_size, embed_dim):
super(SimpleModel, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embed_dim)
self.embeddings.weight.data.copy_(glove.vectors)
def forward(self, input):
return self.embeddings(input)
# Assuming a vocabulary size of 10000
vocab_size = 10000
embed_dim = 100 # Dimension of GloVe vectors
model = SimpleModel(vocab_size, embed_dim)
# Example input: list of indices for words in the sentence
input = torch.tensor([1, 2, 784, 1284], dtype=torch.long)
# Get the embeddings for the input
embeddings = model(input)In this example, we first load the GloVe embeddings using torchtext. We then define a simple model with an embedding layer. The embedding layer's weights are replaced with the GloVe vectors. When we pass a tensor of word indices to the model, it returns the corresponding word embeddings.
Practical Considerations
Handling Unknown Words: In real-world applications, you might encounter words not present in your pre-trained embeddings. A common strategy is to map these to a special "unknown" token in your vocabulary.
Fine-Tuning Embeddings: Depending on your task, you might want to fine-tune the embeddings during training. This can be done by setting
requires_grad=Truefor the embedding layer, allowing the embeddings to be updated during backpropagation.Batch Processing: For efficiency, process your data in batches. Ensure that all sequences in a batch are of the same length by padding shorter sequences.
Working with word embeddings in PyTorch is both flexible and powerful. By leveraging pre-trained embeddings and the tools provided by PyTorch, you can build sophisticated NLP models capable of understanding and processing human language in a nuanced manner.
Conclusion
As we conclude this week's exploration into the advanced world of word embeddings, we have traversed through the intricate landscapes of contextual embeddings, their far-reaching applications, and the challenges that accompany these technological advances. The journey from basic word representations to complex, context-aware models underscores the rapid progress and transformative potential of natural language processing in AI.
Key Takeaways:
The Evolution of Contextual Understanding: We witnessed how the shift from static to dynamic, context-sensitive embeddings like ELMo and BERT has significantly enhanced the way machines understand human language.
Practical Applications Abound: From revolutionizing chatbots and virtual assistants to refining content recommendations and machine translations, the impact of advanced embeddings is evident across numerous domains.
Navigating Challenges: We also acknowledged the hurdles, including computational demands, inherent biases in language models, and the ongoing struggle with out-of-vocabulary words. These challenges remind us that the field is continuously evolving, with each solution paving the way for new questions and explorations.
Implementation Insights: Looking at the practical use of embeddings in PyTorch, we observed how pre-trained models can be effectively utilized and customized, making sophisticated language understanding more accessible.
As we wrap up, it's clear that the realm of word embeddings is not just about understanding words in isolation but about capturing the essence of language in its entirety. The progression towards more nuanced and context-aware models is not just a technical achievement but a step closer to bridging the gap between human and machine communication.
Looking ahead, the insights gleaned from this exploration set a solid foundation for our upcoming discussions on transformers. Transformers represent the next frontier in NLP, building upon the concepts of contextual embeddings to achieve even more remarkable feats in language understanding. Stay tuned as we continue our journey into the exciting world of AI and language processing.
References:
Peters, et al. Deep contextualized word representations, 2018. https://doi.org/10.48550/arXiv.1802.05365
Vaswani, et al. Attention is all you need, 2017. https://doi.org/10.48550/arXiv.1706.03762