


Vision Through Algorithms: The Power of CNNs
Part 1: Foundations – How Convolutional Layers Transform Vision in AI


Introduction
Welcome back to our exploration of machine learning, where we begin to take things deeper. After unraveling the complexities of basic neural networks in our previous sessions, this week, we pivot our focus to one of the most groundbreaking and influential types of neural networks in the field of Artificial Intelligence: Convolutional Neural Networks (CNNs). Predominantly known for their prowess in handling image data, CNNs have revolutionized the way machines interpret visual information. In this first part of our two-week journey into CNNs, we'll lay the groundwork by understanding what exactly sets CNNs apart from traditional neural networks, delving into the mechanics of convolutional layers, and shedding light on the pivotal role of activation functions. Our aim is to build a robust foundation that not only clarifies the basic concepts but also paves the way for deeper exploration into more complex structures and applications of CNNs. So, let's embark on this exciting journey to demystify these powerful neural networks, piece by piece.

The Essence of Convolutional Neural Networks
At the heart of Convolutional Neural Networks (CNNs) lies a simple, yet profound idea: to enable machines to interpret and understand visual data much like the human brain does. While traditional neural networks assume that the input data - typically numerical in form - is flat, CNNs thrive on the inherent structure of data, especially images, recognizing patterns and features through layers of processing.
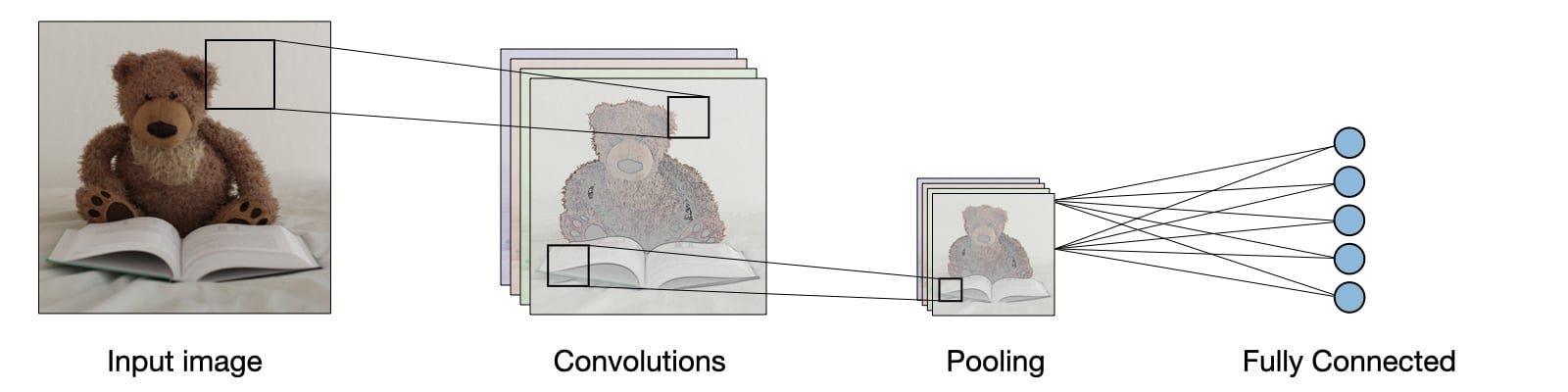
Unraveling the Mysteries of Convolution
The term 'convolution' in CNNs refers to a specialized kind of mathematical operation, a cornerstone of these networks. It's through this process that CNNs can extract meaningful features from raw images. Imagine a filter, or kernel, a small matrix that slides over the input image. As it moves across the image, it performs element-wise multiplication with the part of the image it covers, summing up these results into a single value. This output forms what we call a 'feature map.' The beauty of this process lies in its ability to capture the spatial hierarchies in images - edges, textures, and patterns - which are vital cues for understanding and interpreting visual data.
Filters/Kernels: The Building Blocks
The filters or kernels are not just arbitrary matrices; they are learned features. During training, CNNs automatically learn the optimal values for these filters, enabling them to detect specific features at various levels of abstraction. For instance, initial layers may capture basic edges or textures, while deeper layers can identify more complex patterns, like parts of faces in a facial recognition system.

Feature Maps: A Window to Hidden Patterns
Every filter applied to the image results in a different feature map. These maps are essentially new representations of the original image, highlighting specific features that the filter captures. For instance, one filter might be adept at highlighting vertical edges, while another might emphasize areas with a particular texture. By stacking multiple convolutional layers, each with its own set of filters, CNNs can abstract higher-level features from raw pixel values - a process akin to how our brains perceive and understand visual scenes.

The convolutional layer, with its ability to preserve the spatial relationship between pixels, offers a significant advantage over fully connected layers for image processing. This spatial awareness embedded in CNNs is crucial for tasks where context and texture play a vital role, such as in image classification or object detection.
Through the lens of convolutional layers, CNNs offer a powerful, efficient, and intuitive approach to processing and interpreting image data. This capability not only forms the crux of their application in various image-related tasks but also stands as a testament to the elegant way these networks mimic the complexity of human vision. As we delve deeper into CNNs, their remarkable ability to learn hierarchical patterns continues to unfold, revealing more about their potent capabilities in the realm of artificial intelligence.
Convolutional Layers Explained
In the realm of Convolutional Neural Networks (CNNs), convolutional layers are the cornerstone, playing a pivotal role in enabling these networks to excel in tasks like image recognition. To truly grasp the essence of CNNs, it's crucial to understand what convolutional layers are, how they operate, and why they're so effective.
The Concept of Convolution in Neural Networks
Convolution, in the context of neural networks, refers to a mathematical operation that involves a filter or kernel being applied to an input data. Imagine a small window sliding across an image; this window represents the filter. As it moves, it covers different parts of the image, performing calculations at each step. The primary goal of this operation is to extract features from the input data - be it edges, textures, or specific patterns in the case of images.
Filters/Kernels: The Feature Detectors
The filter, also known as a kernel in this context, is a small matrix of numbers. The essence of convolution lies in how this filter interacts with the input data. For each position of the filter over the input, it performs element-wise multiplication with the part of the input it covers, and the results are summed up. This process generates a new matrix called a feature map.

The beauty of this mechanism is that different filters can extract different kinds of features from the input. For instance, one filter might focus on detecting vertical edges, while another might be tuned to highlight areas with a certain texture. During the training of a CNN, these filters are automatically learned, enabling the network to focus on features that are most relevant for performing a given task.
Feature Maps: Capturing Spatial Hierarchies
The output produced by a convolutional layer is a set of feature maps. Each feature map corresponds to one filter and represents a specific type of feature detected in the input. For instance, in the context of image processing, one feature map might highlight the edges in an image, while another might emphasize areas with a particular color or texture.
What makes convolutional layers truly remarkable is their ability to capture spatial hierarchies. As we stack convolutional layers in a CNN, deeper layers can detect more complex patterns. The first layer might capture simple edges, but as we progress deeper, the subsequent layers can combine these edges to detect shapes and eventually more complex structures like objects in an image.

The Significance in CNNs
The convolutional layer's ability to efficiently process and extract spatial hierarchies of features makes it uniquely suited for tasks involving images, videos, and even other forms of spatial data. This efficient processing is due to the shared weights in the filter and the reduced number of parameters compared to fully connected layers, leading to both computational efficiency and reduced risk of overfitting.
In summary, convolutional layers are the essence of CNNs, providing a mechanism to automatically and efficiently extract and learn features from input data. This ability to learn hierarchical patterns is what makes CNNs so powerful in various applications, particularly those involving visual inputs. By understanding the workings of convolutional layers, we gain insights into the heart of CNNs and what makes them a cornerstone of modern AI and deep learning applications.
Role of Activation Functions in CNNs
In the realm of Convolutional Neural Networks (CNNs), activation functions play a pivotal role, much like the director of an orchestra. These functions are not just a technical detail but the heartbeat of neural networks, determining how the network responds to the input received.
Why Activation Functions Matter: The primary purpose of an activation function in a neural network is to introduce non-linearity. Without these functions, no matter how many layers the network has, it would still behave like a single-layer perceptron because the composition of linear functions is linear. This non-linearity allows the network to capture complex patterns and relationships in the data, which is especially crucial in tasks like image recognition where the nuances and subtleties of pixel data need to be captured accurately.
In CNNs, each convolutional layer is typically followed by an activation function. This sequence ensures that the linear convolutions are transformed, allowing the network to learn more complex representations at each layer.
The Reign of ReLU: Among the various activation functions like sigmoid, tanh, and others, the Rectified Linear Unit (ReLU) has emerged as a popular choice in CNNs. ReLU is defined as f(x) = max(0, x), effectively turning all negative values to zero and maintaining positive values as they are. This simplicity leads to several advantages:
Computational Efficiency: ReLU is computationally inexpensive, making it highly efficient for training large neural networks. This efficiency stems from its simplicity – it involves basic thresholding at zero.
Mitigating the Vanishing Gradient Problem: In deep networks, gradients can become vanishingly small, severely slowing down the training process or stopping it altogether. ReLU alleviates this problem to some extent because the gradient is either zero (for negative inputs) or one (for positive inputs).
Sparse Activation: In a network with ReLU, at any given point, only a subset of neurons is activated, leading to sparse interactions. This sparsity is beneficial as it leads to more efficient models and helps in reducing overfitting to some extent.

However, ReLU is not without its downsides. The most notable one is the “dying ReLU” problem, where neurons can sometimes become inactive and stop contributing to the learning process, especially if they only receive negative input.
Despite this, the benefits of ReLU in practice, particularly in deep learning models like CNNs, often outweigh its disadvantages. Its ability to accelerate the training process and its effectiveness in dealing with complex, hierarchical data structures makes it a cornerstone in CNN architectures.
In conclusion, activation functions, and specifically ReLU in the context of CNNs, are not just mathematical conveniences. They are integral to the network's ability to learn, adapt, and make nuanced predictions. By introducing non-linearity, they enable CNNs to go beyond mere data fitting to true data understanding, making them a critical component in the deep learning toolkit.
Conclusion
As we conclude the first part of our exploration into Convolutional Neural Networks (CNNs), let's reflect on what we've learned:
CNNs' Role in Deep Learning: We started by understanding the unique position CNNs hold in the realm of deep learning, especially in handling grid-like data such as images.
Convolutional Layers: The heart of CNNs lies in their ability to extract features using convolutional layers. We unpacked how convolution works and its pivotal role in detecting features like edges, textures, and more complex patterns in input data.
Filters/Kernels: We learned about filters or kernels, the driving force in convolutional layers, which slide over input data to create feature maps.
Feature Maps: These maps are the results of applying filters to the input, highlighting important features in the data.
Activation Functions: We touched upon why activation functions, particularly ReLU (Rectified Linear Unit), are critical in introducing non-linearity to the network, enabling it to learn complex patterns.
Through this journey, we’ve only scratched the surface of CNNs. These concepts lay the groundwork for understanding more complex architectures and applications of CNNs.
Teaser for Part 2
But what's next? In Part 2 of our CNN series, we will dive deeper into the architecture of CNNs:
Pooling Layers: We'll explore how pooling layers reduce the spatial size of the feature maps, making the computation more manageable and extracting dominant features while reducing overfitting.
Building a Basic CNN Architecture: We will piece together the knowledge of convolutional and pooling layers to understand how a basic CNN is structured. This will set the stage for understanding more complex and deeper networks.
Practical Application – Image Recognition: We'll look at a practical application of CNNs in image recognition, illustrating how these networks make sense of pixel data to recognize patterns and objects.
And More: Be prepared to dig into the nuances that make CNNs a powerful tool in the machine learning toolkit.
Stay tuned for a more in-depth exploration as we continue to unravel the complexities and capabilities of Convolutional Neural Networks. Be sure to join us in Week 7, Part 2, for this exciting journey!
References
Convolutional Neural Network Cheatsheet: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems 25 (2012): 1097-1105