


Introduction: Unraveling the Mysteries of Self-Attention and Positional Encodings
As we venture deeper into our exploration of Transformers, week 2 of our series focuses on two pivotal components that stand at the heart of this revolutionary architecture: self-attention and positional encodings. These mechanisms are not just integral to understanding how Transformers operate but are also key to their extraordinary ability to process and generate language with remarkable nuance and coherence.

Self-Attention: The Art of Contextual Awareness
Self-attention, the cornerstone of the Transformer model, redefines how we approach sequence modeling. This week, we'll dissect how this mechanism allows Transformers to weigh the importance of each word in a sentence in relation to every other word, enabling a dynamic understanding of context that surpasses previous models. By capturing these intricate relationships, self-attention facilitates a level of language understanding that mirrors human intuition, allowing for more accurate predictions and more nuanced text generation.
Positional Encodings: Understanding Sequence Order
In the absence of recurrent or convolutional structures, Transformers rely on positional encodings to comprehend the order of words in a sentence. This week, we will explore how these encodings inject sequence information into the model, ensuring that the meaning derived from word order is not lost. Positional encodings are crucial for the model to grasp the directional flow of language, from the significance of word placement to the understanding of temporal sequences in text.

The Mechanics of Self-Attention
Self-attention, a transformative concept at the core of the Transformer architecture, has been pivotal in enabling models to understand and generate language with unprecedented nuance. This section covers the intricacies of self-attention, exploring how it processes sequences to capture the complex interdependencies between words.
Understanding Self-Attention
Self-attention, sometimes referred to as intra-attention, is a mechanism that allows each element in a sequence to interact with every other element to dynamically weigh and derive context. Unlike traditional models that process elements sequentially, self-attention considers the entire sequence simultaneously, enabling the model to capture relationships between words regardless of their positional distance from each other.
How Self-Attention Works:
Query, Key, and Value Vectors: For each word in the input sequence, the self-attention mechanism generates three vectors from its embedding: a query vector, a key vector, and a value vector. These vectors are produced through learned linear transformations, and they play distinct roles in the attention mechanism.
Attention Score Calculation: The mechanism calculates an attention score by performing a dot product between the query vector of each word and the key vector of every other word. This score determines how much focus should be given to other parts of the input sequence when encoding a particular word.
Softmax Normalization: The attention scores are then normalized using a softmax function. This step ensures that the scores across the sequence sum up to 1, converting them into probabilities that signify the relative importance of each word's information.
Weighted Sum of Value Vectors: Each word's output is computed as a weighted sum of all value vectors, with weights specified by the softmax-normalized attention scores. This output reflects both the word's original meaning and the context provided by the entire sequence.
Combining Outputs for Final Representation: The outputs for each word are combined to form the final representation of the sequence, which is then passed through the rest of the Transformer model.
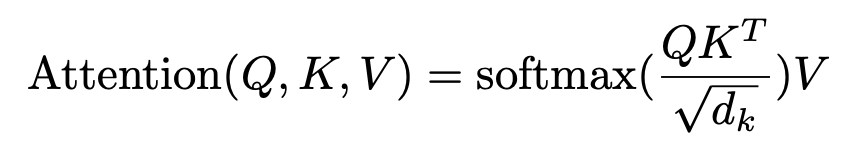
Let’s visualize the steps to compute an attention score given inputs as well as the Query, Key, and Value vectors. First, the query vector (Q) is multiplied by the transpose of the key vector (K) to calculate attention scores. Then these scores are divided by the square root of the dimension of the key (square root(dk)) to normalize, followed by applying the softmax function to convert scores into probabilities. Finally, these probabilities are multiplied by the value vector (V) to produce the output of the attention mechanism.

The Significance of Self-Attention
Flexibility in Capturing Dependencies: Self-attention's ability to weigh the importance of all words in the sequence relative to each other allows it to capture long-range dependencies, making it highly effective for complex sentence structures.
Parallelization and Efficiency: By processing all words simultaneously, self-attention enables the parallelization of computations, significantly enhancing the model's efficiency and training speed.
Dynamic Contextual Understanding: Unlike fixed embeddings, the context-sensitive nature of self-attention ensures that the representation of each word is dynamically influenced by its surrounding words, leading to a more nuanced understanding of language.

Applications and Implications
The self-attention mechanism has not only revolutionized NLP tasks such as translation, summarization, and text generation but also paved the way for innovations in other domains, like computer vision, through adaptations like Vision Transformers (ViTs). Its ability to model complex relationships and contexts within data makes it a versatile tool for a wide range of AI challenges.
In essence, self-attention is the driving force behind the Transformer model's success, enabling it to capture the subtleties of human language and thought processes. As we continue to explore and refine this mechanism, its potential to enhance machine understanding and generation of natural language seems boundless.
Unpacking Positional Encodings
In a Transformer model, positional encodings serve as a crucial component, compensating for the architecture's lack of recurrence by embedding sequence order information directly into the input embeddings. This section explores the concept of positional encodings, their implementation, and their significance in preserving the notion of sequence within Transformer models.
The Role of Positional Encodings
Transformers, by design, process input sequences in parallel, lacking an inherent mechanism to recognize the order of elements within the sequence. Positional encodings address this gap by providing a unique signature for each position in the sequence, thereby enabling the model to distinguish the order of words or tokens.
How Positional Encodings Work:
Design Principle: Positional encodings are designed to be added to the input embeddings before they are fed into the Transformer model. These encodings can take various forms, but they all aim to encode the position of each token in the sequence uniquely.
Encoding Strategy: The original Transformer model uses a specific mathematical formula for positional encodings, involving sine and cosine functions of different frequencies. This approach ensures that each position produces a unique encoding, and patterns in the encoding help the model to learn relative and absolute positions of tokens.
Addition to Input Embeddings: The positional encoding for each token's position is added to its corresponding input embedding, resulting in a position-aware input vector. This process allows the model to maintain awareness of sequence order throughout its layers.

The foundational paper on Transformers introduced the use of sine and cosine functions at varying frequencies for positional encodings, enabling the model to differentiate positions by attending to these distinct frequency patterns.
Significance of Positional Encodings
Sequence Order Awareness: By integrating positional information with the input embeddings, positional encodings enable Transformer models to understand the order of tokens in a sequence, a critical aspect for tasks like language translation and text generation.
Enabling Relative Positioning: The specific patterns used in positional encodings (e.g., sinusoidal functions) allow the model not just to recognize the sequence order but also to infer relative distances between tokens, enhancing its ability to understand context and relationships within the data.
Flexibility and Efficiency: Unlike recurrent neural networks, which process sequences step-by-step, positional encodings allow Transformers to benefit from parallel processing while still maintaining sequence awareness, significantly improving computational efficiency.

Variations and Innovations
Since the introduction of the original Transformer, various modifications and alternatives to positional encodings have been proposed to further enhance the model's efficiency and accuracy. These include learnable positional encodings and relative positional encodings, among others, each with its own set of advantages and tailored to specific applications.
Applications Beyond Text
Positional encodings have proven to be a versatile concept, applicable not only in NLP but also in other domains like computer vision and time-series analysis, where the notion of order or position plays a crucial role in understanding the data.
The introduction of positional encodings into Transformer models represents a simple yet profound solution to sequence modeling challenges, enabling these architectures to achieve groundbreaking performance across a wide range of tasks. As we continue to explore and refine these concepts, the potential for new applications and innovations remains vast, promising further advancements in the field of AI.
Conclusion
As we conclude our exploration of self-attention and positional encodings, we've covered the core mechanisms that empower Transformer models to revolutionize the processing of sequential data. Self-attention, with its ability to dynamically weigh and integrate context from all parts of the input, offers a nuanced understanding of language and relationships within data. Coupled with positional encodings, which imbue the model with a sense of sequence order, Transformers achieve a remarkable balance between parallel processing efficiency and deep contextual awareness.
This week's journey underscores the ingenuity behind Transformer architecture, revealing how these models maintain sequence sensitivity without relying on traditional recurrent methods. As we've seen, the implications of these innovations extend far beyond natural language processing, offering a blueprint for tackling a broad spectrum of challenges in artificial intelligence.
Looking ahead, the concepts of self-attention and positional encodings lay a solid foundation for understanding the advanced functionalities and diverse applications of Transformer models. Their significance in the AI landscape cannot be overstated, as they continue to inspire new architectures and approaches in machine learning.
As we move forward, our series will continue to unravel the complexities and potentials of Transformers, guiding you through their most influential implementations and practical applications. Stay tuned as we further explore the transformative impact these models have on the field of AI. Thank you for reading!
References:
Vaswani, et al. Attention Is All You Need, 2017. https://doi.org/10.48550/arXiv.1706.03762