
Recommender Systems with PyTorch, Part III [Code Included]
From Data to Decisions: A Journey Through AI-Powered Recommendations


Introduction
Welcome back to our series on recommender systems. Last week, we explored the complexities of collaborative filtering, setting the stage for this week's practical application: building a movie recommender system using PyTorch. PyTorch's dynamic features make it an ideal platform for such a task, offering both flexibility and power.

Our focus will be on the MovieLens dataset, a compact yet insightful collection of movie ratings, perfect for demonstrating the capabilities of a recommender system. We'll guide you through each step - from data preprocessing to model training and evaluation in PyTorch.
By the end of this post, you'll gain hands-on experience in developing a basic recommender system using PyTorch, equipped with the skills to tackle real-world data and modeling challenges.
Why PyTorch is Ideal for Building Recommender Systems
PyTorch stands out in building recommender systems due to its intuitive interface, dynamic computational graph, and robust GPU acceleration, enabling rapid prototyping and efficient handling of large datasets. Its seamless integration with popular Python libraries and strong community support further enhances its suitability for developing sophisticated recommender algorithms. For a deeper dive into PyTorch's capabilities, the PyTorch documentation is an invaluable resource.
Defining the Dataset and Relevant Class
In this section, we dive into the practical steps of setting up our recommender system. We'll be using the widely recognized MovieLens dataset, specifically a file named ratings.csv, which contains user ratings for various movies. This file includes features like userId, movieId, rating (ranging from 1.0 to 5.0), and timestamp.
First, let's load and examine our dataset using Pandas:
import pandas as pd
df = pd.read_csv("ml-latest-small/ratings.csv")
df.head()
Output:
userId movieId rating timestamp
0 1 1 4.0 964982703
1 1 3 4.0 964981247
2 1 6 4.0 964982224
3 1 47 5.0 964983815
4 1 50 5.0 964982931This code snippet loads the data into a Pandas DataFrame and displays the first few entries, giving us a glimpse into the structure of our data.
Next, we define a custom dataset class, MovieLensDataset, which is a crucial component for handling data in PyTorch. This class will prepare the dataset for training and validation processes. PyTorch's dataset class requires defining at least two methods: __len__() to return the size of the dataset, and __getitem__() to support the indexing such that dataset[i] can be used to get the ith sample.
Let's dive into the code for our MovieLensDataset class:
class MovieLensDataset(Dataset):
"""
The Movie Lens Dataset class. This class prepares the dataset for training and validation.
"""
def __init__(self, users, movies, ratings):
"""
Initializes the dataset object with user, movie, and rating data.
"""
self.users = users
self.movies = movies
self.ratings = ratings
def __len__(self):
"""
Returns the total number of samples in the dataset.
"""
return len(self.users)
def __getitem__(self, item):
"""
Retrieves a sample from the dataset at the specified index.
"""
users = self.users[item]
movies = self.movies[item]
ratings = self.ratings[item]
return {
"users": torch.tensor(users, dtype=torch.long),
"movies": torch.tensor(movies, dtype=torch.long),
"ratings": torch.tensor(ratings, dtype=torch.float),
}In this class, the __init__ method initializes the dataset with user IDs, movie IDs, and their corresponding ratings. The __len__ method returns the size of the dataset, which is the total number of ratings. The __getitem__ method, perhaps the most critical, is used to retrieve a specific data sample. Here, we fetch the user ID, movie ID, and rating for a given index and return them as PyTorch tensors, ensuring compatibility with PyTorch's model training processes.
By structuring our dataset in this manner, we enable efficient data handling and batching, which are vital for training neural network models in PyTorch.
Building the Recommender System Model
In this section, we will dive into the core of building a recommender system using PyTorch, focusing on our RecommendationSystemModel class. Our goal is to create a model that can predict how a user might rate movies they haven't seen yet.
Understanding the RecommendationSystemModel
The RecommendationSystemModel class in PyTorch is a neural network designed for making recommendations. Here's an overview of its structure:
Embeddings: The model uses embedding layers for users and movies. Embeddings are a powerful tool in machine learning, especially in recommendation systems, as they provide a way to transform categorical data (like user IDs and movie IDs) into a continuous space. This continuous representation allows the model to capture and learn the intricate relationships and patterns in the data.
Hidden Layers and Non-Linearity: After combining user and movie embeddings, the data is passed through fully connected layers (also known as dense layers) with ReLU (Rectified Linear Unit) activation. These layers allow the model to learn complex relationships in the data.
Dropout: A dropout layer is included to prevent overfitting, which is a common problem in machine learning where the model performs well on training data but poorly on unseen data.
Why Use Embeddings?
The use of embeddings is particularly interesting and crucial in this model. Here’s why:
Dimensionality Reduction: Embeddings help in reducing the dimensionality of the input space. User IDs and movie IDs are categorical variables with potentially thousands of categories. Representing these directly would be highly inefficient and sparse. Embeddings map these IDs into a lower-dimensional space where similar users and movies are closer together.
Learning User and Movie Features: During training, the embeddings learn to capture the latent (hidden) features of users and movies. For instance, in the movie space, embeddings might capture genres, while in the user space, they might capture preferences. This is essentially a form of collaborative filtering, as the model learns from user-item interactions.
Collaborative Filtering Aspect: As the model trains, user and movie embeddings are adjusted to minimize the prediction error. This means that users who have rated movies similarly will end up having similar embeddings. The same goes for movies that have been rated similarly by users. Therefore, the embeddings are learning the collaborative filtering aspect implicitly.
The Forward Method
In the forward method of our model, we perform the following steps:
Generate Embeddings: We first generate embeddings for users and movies.
Combine Embeddings: These embeddings are then concatenated. This combination is a crucial step as it merges user and movie information into a unified representation.
Pass Through Hidden Layers: The combined data then passes through fully connected layers with ReLU activation and dropout. These layers are where the model learns to predict ratings based on the combined user-movie representation.
Output: The final layer outputs the predicted rating.
class RecommendationSystemModel(nn.Module):
def __init__(
self,
num_users,
num_movies,
embedding_size=256,
hidden_dim=256,
dropout_rate=0.2,
):
super(RecommendationSystemModel, self).__init__()
self.num_users = num_users
self.num_movies = num_movies
self.embedding_size = embedding_size
self.hidden_dim = hidden_dim
# Embedding layers
self.user_embedding = nn.Embedding(
num_embeddings=self.num_users, embedding_dim=self.embedding_size
)
self.movie_embedding = nn.Embedding(
num_embeddings=self.num_movies, embedding_dim=self.embedding_size
)
# Hidden layers
self.fc1 = nn.Linear(2 * self.embedding_size, self.hidden_dim)
self.fc2 = nn.Linear(self.hidden_dim, 1)
# Dropout layer
self.dropout = nn.Dropout(p=dropout_rate)
# Activation function
self.relu = nn.ReLU()
def forward(self, users, movies):
# Embeddings
user_embedded = self.user_embedding(users)
movie_embedded = self.movie_embedding(movies)
# Concatenate user and movie embeddings
combined = torch.cat([user_embedded, movie_embedded], dim=1)
# Pass through hidden layers with ReLU activation and dropout
x = self.relu(self.fc1(combined))
x = self.dropout(x)
output = self.fc2(x)
return outputConstructing Data Loaders for Training and Validation
In this part, we will cover the practical steps of preparing our data for the recommender system.
Data Preprocessing and Encoding
Before feeding our data into a model, it's crucial to preprocess and encode it appropriately. We'll use the LabelEncoder from Scikit-learn's preprocessing module to convert the userId and movieId fields into a format suitable for our model. This encoding step transforms the categorical user and movie IDs into a numerical format, which is a common practice in machine learning:
from sklearn import preprocessing
le_user = preprocessing.LabelEncoder()
le_movie = preprocessing.LabelEncoder()
df.userId = lbl_user.fit_transform(df.userId.values)
df.movieId = lbl_movie.fit_transform(df.movieId.values)Splitting the Dataset
Next, we split our dataset into training and validation sets using Scikit-learn's train_test_split function. We stratify the split based on the rating values to ensure that both sets are representative of the overall distribution of ratings:
from sklearn import model_selection
df_train, df_val = model_selection.train_test_split(
df, test_size=0.1, random_state=3, stratify=df.rating.values
)Initializing Data Loaders
Now comes a critical part: initializing our data loaders. In PyTorch, a DataLoader is responsible for managing batches of data, shuffling them (if necessary), and providing an interface to iterate over our dataset during training and validation. Here, we define two loaders: one for training and another for validation:
from torch.utils.data import DataLoader
BATCH_SIZE = 32
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=8)
val_loader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=8)Define the Training Loop
In this section, we define and set up the training loop for our recommender system. The process starts by allocating the model to the appropriate device (CPU/GPU) using .to(device), harnessing GPU acceleration when available. We utilize the Adam optimizer for its balance of efficiency and effectiveness and adopt Mean Squared Error Loss (MSELoss) suitable for our recommendation task. The training loop is then implemented, where each epoch represents a full pass over the dataset, and within these, iterations involve batching data and feeding it into the model. The forward pass includes feeding user and movie inputs to the model and generating rating predictions, followed by loss calculation, where we compare these predictions against actual ratings. Subsequently, the backward pass involves zeroing out gradients, performing backpropagation, and updating model parameters. Finally, we monitor training progress by tracking and averaging loss over steps and employing sys.stderr.write for real-time updates on training metrics, such as the current epoch, step, and average loss, ensuring transparency and control over the training process.
recommendation_model = RecommendationSystemModel(
num_users=len(le_user.classes_),
num_movies=len(le_movie.classes_),
embedding_size=128,
hidden_dim=256,
dropout_rate=0.1,
).to(device)
optimizer = torch.optim.Adam(recommendation_model.parameters(), lr=1e-3)
loss_func = nn.MSELoss()
EPOCHS = 2
# Function to log progress
def log_progress(epoch, step, total_loss, log_progress_step, data_size, losses):
avg_loss = total_loss / log_progress_step
sys.stderr.write(
f"\r{epoch+1:02d}/{EPOCHS:02d} | Step: {step}/{data_size} | Avg Loss: {avg_loss:<6.9f}"
)
sys.stderr.flush()
losses.append(avg_loss)
total_loss = 0
log_progress_step = 100
losses = []
train_dataset_size = len(train_dataset)
print(f"Training on {train_dataset_size} samples...")
recommendation_model.train()
for e in range(EPOCHS):
step_count = 0 # Reset step count at the beginning of each epoch
for i, train_data in enumerate(train_loader):
output = recommendation_model(
train_data["users"].to(device), train_data["movies"].to(device)
)
# Reshape the model output to match the target's shape
output = output.squeeze() # Removes the singleton dimension
ratings = (
train_data["ratings"].to(torch.float32).to(device)
) # Assuming ratings is already 1D
loss = loss_func(output, ratings)
total_loss += loss.sum().item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Increment step count by the actual size of the batch
step_count += len(train_data["users"])
# Check if it's time to log progress
if (
step_count % log_progress_step == 0 or i == len(train_loader) - 1
): # Log at the end of each epoch
log_progress(
e, step_count, total_loss, log_progress_step, train_dataset_size, losses
)
total_loss = 0Visual Feedback
During training we stored the average losses in a list. We can visualize them in a plot. We expect to see the loss decrease over training time.
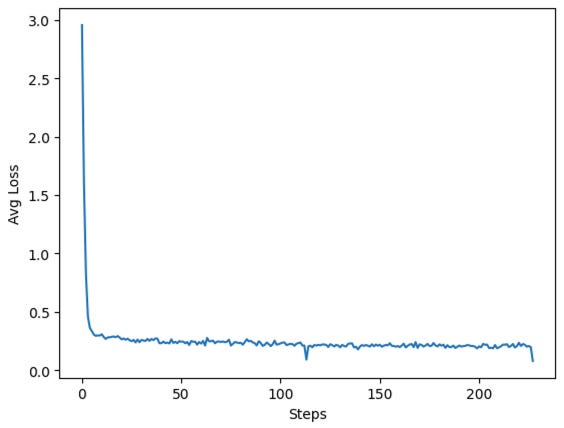
Analyzing Model Training: RMS and Precision@k/Recall@k
In the realm of recommender systems, evaluating the performance of our model is crucial to ensure its effectiveness. Two critical aspects of this evaluation are the accuracy of predicted ratings and the relevance of the recommendations made. To measure these, we use Root Mean Square Error (RMS) for accuracy and precision@k and recall@k for relevance. Let's dive into how these metrics are computed and interpreted.
RMS (Root Mean Square Error)
RMS is a standard measure to evaluate the accuracy of predicted ratings. It provides an aggregated measure of the magnitude of errors between the predicted and actual ratings. Lower RMS values indicate higher accuracy. Here's how we compute RMS in our model:
from sklearn.metrics import mean_squared_error
y_pred = []
y_true = []
recommendation_model.eval()
with torch.no_grad():
for i, valid_data in enumerate(val_loader):
output = recommendation_model(
valid_data["users"].to(device), valid_data["movies"].to(device)
)
ratings = valid_data["ratings"].to(device)
y_pred.extend(output.cpu().numpy())
y_true.extend(ratings.cpu().numpy())
# Calculate RMSE
rms = mean_squared_error(y_true, y_pred, squared=False)
print(f"RMSE: {rms:.4f}")In this code, we first gather the predicted and actual ratings for each instance in our validation dataset. We extend the lists y_pred and y_true with individual predicted and true rating values for each instance. Then, we compute the mean squared error (MSE) between these two lists using scikit-learn's mean_squared_error function and take the square root to get the RMSE. This gives us a single value representing the average prediction error across all individual ratings.
Precision@k and Recall@k
Precision@k and recall@k are metrics used to evaluate the relevance of the recommendations. In the context of recommender systems, precision@k measures the proportion of recommended items in the top-k set that are relevant, while recall@k measures the proportion of relevant items found in the top-k recommendations. Here’s how these are calculated:
from collections import defaultdict
def calculate_precision_recall(user_ratings, k, threshold):
user_ratings.sort(key=lambda x: x[0], reverse=True)
n_rel = sum(true_r >= threshold for _, true_r in user_ratings)
n_rec_k = sum(est >= threshold for est, _ in user_ratings[:k])
n_rel_and_rec_k = sum((true_r >= threshold) and (est >= threshold) for est, true_r in user_ratings[:k])
precision = n_rel_and_rec_k / n_rec_k if n_rec_k != 0 else 1
recall = n_rel_and_rec_k / n_rel if n_rel != 0 else 1
return precision, recall
user_ratings_comparison = defaultdict(list)
with torch.no_grad():
for valid_data in val_loader:
users = valid_data["users"].to(device)
movies = valid_data["movies"].to(device)
ratings = valid_data["ratings"].to(device)
output = recommendation_model(users, movies)
for user, pred, true in zip(users, output, ratings):
user_ratings_comparison[user.item()].append((pred[0].item(), true.item()))
user_precisions = dict()
user_based_recalls = dict()
k = 50
threshold = 3
for user_id, user_ratings in user_ratings_comparison.items():
precision, recall = calculate_precision_recall(user_ratings, k, threshold)
user_precisions[user_id] = precision
user_based_recalls[user_id] = recall
average_precision = sum(prec for prec in user_precisions.values()) / len(user_precisions)
average_recall = sum(rec for rec in user_based_recalls.values()) / len(user_based_recalls)
print(f"precision @ {k}: {average_precision:.4f}")
print(f"recall @ {k}: {average_recall:.4f}")
Output:
precision @ 50: 0.8961
recall @ 50: 0.8647In this segment, we first generate predictions for each user-movie pair in the validation set and store them along with the actual ratings. Then, we compute precision and recall for each user. Precision is calculated as the ratio of relevant items (ratings above a certain threshold) in the top-k recommendations to the total number of recommendations made, while recall is the ratio of relevant items in the top-k recommendations to the total number of relevant items.
The provided values for RMS (Root Mean Square Error), precision@k, and recall@k give us valuable insights into the performance of the recommender system. Let's interpret each of these metrics in the given context:
Root Mean Square Error (RMSE): 0.1760
What It Measures: RMSE is a standard way to measure the error of a model in predicting quantitative data. In our case, it's used to evaluate how accurately the recommendation model predicts the ratings of movies.
Interpretation: A lower RMSE value indicates better performance. An RMSE of
0.1760suggests that, on average, the predicted ratings deviate from the actual ratings by0.1760points (on the rating scale used in MovieLens, typically 1 to 5).Since the ratings are on a 1-5 scale, this error can be considered relatively low, indicating good predictive accuracy.
Precision @ 50: 0.8961
What It Measures: Precision in the context of a recommendation system is the proportion of recommended items that are relevant. Precision @ 50 means the precision calculated by considering the top 50 recommendations made by the system.
Interpretation: A precision of
0.8961means that about 89.61% of the top 50 movies recommended by the system are relevant to the users.This is a high precision rate, suggesting that the model is very effective at identifying movies that users will rate positively. However, we should note that precision alone doesn't account for the completeness of the recommendations.
Recall @ 50: 0.8647
What It Measures: Recall measures the proportion of relevant items that are successfully recommended. Recall @ 50 assesses what percentage of the movies that should have been in the top 50 recommendations were actually recommended.
Interpretation: A recall of
0.8647indicates that the system successfully recommended about 86.47% of the movies that are relevant to users and should have been in the top 50 recommendations.This is also a relatively high score, implying that the system is good at capturing relevant movies. However, it's not perfect, and there's a small portion of relevant movies that it's missing.
Overall Assessment
Balanced Performance: Our model shows a good balance between precision and recall, suggesting it is both accurate and comprehensive in its recommendations.
Good Predictive Accuracy: The low RMSE value indicates good predictive accuracy in terms of rating predictions.
Future Improvements: While these metrics are strong, it's important to consider additional factors such as the diversity of recommendations and user coverage. Also, it would be beneficial to analyze how the model performs across different user segments and types of movies.
Possible Pitfalls: We should be aware of potential biases in the data or the model, such as popularity bias, where popular movies are more likely to be recommended.
Predicting Top Movies a User Hasn’t Seen
After developing a recommendation model, we can predict a user's top movies that they haven't seen yet. This process involves analyzing their viewing history and preferences. For instance, based on a user's history of watching films like 'High Noon (1952) - Drama|Western' and 'Hannah and Her Sisters (1986) - Comedy|Drama|Romance', the model can identify patterns and preferences in genres and themes. Utilizing these insights, it then predicts and recommends movies such as 'North by Northwest (1959) - Action|Adventure|Mystery|Romance|Thriller' and 'The Lost Weekend (1945) - Drama' which the user is likely to enjoy but hasn't seen yet. This personalized recommendation enhances the user's viewing experience by suggesting new movies that align closely with their tastes and preferences. You can explore more about how this is done in the method recommend_top_movies in the code.
Recommended movies:
[
'North by Northwest (1959) - Action|Adventure|Mystery|Romance|Thriller', 'Lost Weekend, The (1945) - Drama',
'Blood Feast (1963) - Horror'
]
based on these movies the user has watched and rated highly:
[
'High Noon (1952) - Drama|Western',
'Hannah and Her Sisters (1986) - Comedy|Drama|Romance',
'After Hours (1985) - Comedy|Thriller',
'AVP: Alien vs. Predator (2004) - Action|Horror|Sci-Fi|Thriller'
]Conclusion
In our latest exploration, we've taken a deep dive into the realm of recommender systems, harnessing the power of PyTorch to construct and refine a neural network. Our focus has been on critical evaluation metrics: RMS, precision@k, and recall@k, providing a clear lens through which to assess our model's performance.
This week's insights have not only shed light on the current capabilities of our recommender system but have also paved the way for future enhancements. As we progress, our aim will be to strike a balance between precision and recall, ensuring our predictions remain both accurate and relevant. The journey in AI and ML is an ever-evolving one, filled with opportunities for growth and learning, and our project is a testament to this ongoing adventure.
📣 Next week, we're excited to embark on a more extensive series focusing on Generative AI. Stay tuned as we dive deeper into this fascinating aspect of artificial intelligence, exploring its potential and the innovative ways it's being applied in the field!
Thank you for reading!
GitHub Code
If you’d like to dive further into the code, you can find it here.
Hello there! Root Mean Square Error (RMSE): 0.1760 - is this a typo? My code achieves 0.79 RMSE. Looks like existing opensource benchmarks are also of that order of magnitude, though it is hard to say for sure because train/test split is different in each case
Awesome resource! The link to the code isn't working though, any chance this can be fixed?