
Decoding AI Decisions: Interpreting MNIST CNN Models Using LIME
A Practical Guide with LIME and MNIST to Better Understand AI Predictions


Introduction
As AI continues to advance, understanding the inner workings of complex models like Convolutional Neural Networks (CNNs) is crucial. While our previous journey through the MNIST dataset using a CNN showcased its effectiveness in digit classification, the reasoning behind its decisions largely remained a mystery. This is where Explainable AI (XAI) and specifically LIME (Local Interpretable Model-agnostic Explanations) come into play.

In this post, we'll revisit the MNIST CNN model, integrating it with LIME to unveil how the model interprets data to make predictions. By doing so, we aim to transform the 'black box' of our CNN into a more transparent and understandable system. This not only enhances trust in the model's decisions but also opens up avenues for further improvements and insights.
Background on Explainable AI
The Rise of the Black Box
In the world of artificial intelligence, deep learning models, especially Convolutional Neural Networks (CNNs), have gained prominence for their remarkable ability to learn from vast amounts of data. These models have become the backbone of complex tasks such as image and speech recognition, natural language processing, and more. However, their success comes with a caveat: they often act as 'black boxes.' While these models can make highly accurate predictions, understanding the 'why' and 'how' behind these predictions remains a challenge. This opacity in decision-making processes poses significant issues, particularly in sectors where transparency and trust are paramount, such as healthcare, finance, and autonomous vehicles.
The Need for Explainable AI
Enter Explainable AI (XAI). XAI refers to techniques and methods that make the outputs of AI systems more understandable to humans. The goal of XAI is to bridge the gap between the high performance of AI models and the human need for understanding and trust. It’s not just about making models transparent, but about building user trust, ensuring regulatory compliance, and providing insights that can help improve the model's performance and fairness. In a world increasingly reliant on AI decisions, the ability to explain and validate these decisions is crucial.

XAI in Practice
XAI encompasses a range of approaches. Some focus on the model itself, attempting to simplify or visualize the model's inner workings. Others, like LIME (Local Interpretable Model-agnostic Explanations), take a different approach. LIME provides explanations for individual predictions, offering insights into why a model made a specific decision. This method is particularly useful for complex models like CNNs, where direct interpretation of the model's internal structure is challenging.
The Balancing Act
However, it's important to note that there is often a trade-off between model complexity and interpretability. Simpler models like decision trees or linear regression are inherently more interpretable but might not achieve the high accuracy of complex models like CNNs. XAI strives to find a balance, providing clarity without significantly compromising performance.
Moving Forward
As AI continues to advance and integrate into more aspects of our lives, the importance of explainability grows. XAI isn't just a technical requirement; it's a move towards more ethical, transparent, and accountable AI. By demystifying the decision-making processes of AI models, we can foster greater trust and acceptance among users and stakeholders, paving the way for more responsible and effective use of AI technologies.
Introduction to LIME
The Essence of LIME in AI's World
Following our exploration of the critical need for XAI, let's introduce LIME, a pivotal tool in the XAI toolbox. Local Interpretable Model-agnostic Explanations, or LIME, is a novel approach designed to demystify the decision-making processes of complex machine learning models. Its core function is to provide understandable explanations for individual predictions, regardless of the model's inherent complexity.
Model-Agnostic: LIME's Universal Appeal
One of LIME's most compelling features is its model-agnostic nature. This means that LIME can be applied to a wide range of machine learning models, from simple linear regressions to intricate deep learning models like CNNs. This versatility makes LIME an invaluable asset in the XAI domain, as it can adapt to various modeling techniques, offering insights into diverse AI applications.

LIME with CNNs for MNIST Classification
For our exploration, we focus on utilizing LIME in conjunction with a Convolutional Neural Network (CNN). CNNs, renowned for their prowess in image processing and classification tasks, are an ideal candidate for LIME's interpretability. Our model, which has been trained to classify the MNIST dataset—a collection of handwritten digits—provides a tangible example to illustrate LIME's capability. By applying LIME to our CNN, we aim to unveil how the model perceives and interprets the features of handwritten digits, shedding light on the 'why' and 'how' behind its predictions.
How Does LIME Work?
LIME begins by selecting an individual prediction to explain. It then generates a new dataset consisting of perturbed samples around that specific instance and obtains predictions for these new samples from the model. By doing so, LIME observes how the predictions change with the variations in the input. It then uses this information to create a simple, locally faithful model (like a linear model) that approximates the behavior of the complex model around that particular instance. This simpler model is interpretable and can reveal which features significantly influenced the prediction for that specific case.
The Impact of LIME in AI Interpretability
By integrating LIME into our analysis, we aim to achieve a more transparent AI ecosystem, particularly in the realm of image classification. LIME's insights can enhance our understanding of model behavior, assist in debugging and improving model performance, and, crucially, build trust among users and stakeholders. As AI systems increasingly impact various sectors, the ability to explain their decisions becomes not just a technical necessity but a cornerstone for ethical and responsible AI development.
Integrating LIME with the MNIST CNN Model
Collecting Sample Images
The first step involves collecting sample images from the MNIST dataset, one for each digit (0-9). This is achieved using a simple loop that iterates over the test dataset to find and store one example image per digit class.
Segmentation for Superpixels
The next step involves setting up a segmentation function. Here, we use the 'slic' algorithm for segmentation, which helps in dividing the image into 'superpixels'. These superpixels are crucial for LIME as they act as interpretable components the algorithm can use to explain the model's predictions.
Applying LIME to Each Digit
For each digit, we apply LIME to the corresponding image. The explainer.explain_instance method is pivotal here. It generates explanations for why the CNN model predicts a certain class for each image. By specifying parameters like top_labels, num_samples, and segmentation_fn, we control how the explanation is generated and how detailed it should be.
Visualizing the Explanations
The final, and arguably the most insightful, part is visualizing these explanations. For each digit, we extract the image and mask from the explanation object. This mask highlights the superpixels most influential in the model's prediction.

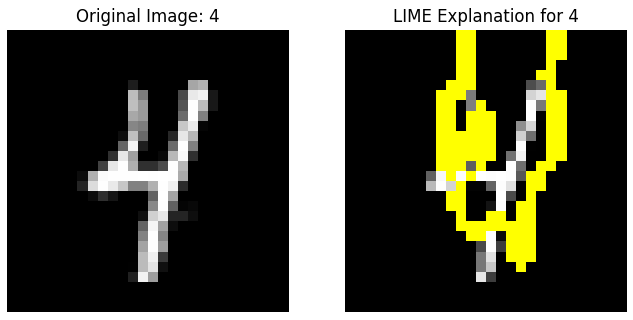

The side-by-side plots of the original image and its LIME explanation offer a striking comparison. This visualization is key to understanding how the model perceives different features of each digit. The images labeled 'LIME Explanation for [X]' reveal which specific areas and patterns of the digit were most significant for the model's decision-making process. We can see for these digits, the model focuses on the presence of straight lines and angles. These characteristics serve as distinctive features for these particular digits, enabling the model to effectively differentiate them from other numbers. This insight underscores the model's reliance on specific geometric traits in its decision-making process for digit recognition. You can explore more of the results in the linked GitHub code below.
Conclusion
In this post, we've taken a significant step towards demystifying the workings of AI by applying LIME to our MNIST CNN model. This approach has shed light on how the model interprets handwritten digits, providing us with valuable insights into the features that drive its predictions.
The use of tools like LIME in XAI is crucial in building trust and understanding in AI systems. It helps us not just in appreciating the model's accuracy but also in understanding its decision-making process. However, it's important to remember that these tools are aids, not definitive answers. They should be part of a broader strategy to assess and validate AI models.
As we continue to integrate AI more deeply into various sectors, the importance of transparency and explainability grows. I encourage you to explore these interpretability techniques further and join the conversation on responsible AI development.
Your experiences and experiments can contribute greatly to this evolving field. Share your stories and let’s navigate the fascinating world of AI together with a focus on informed and responsible use.
GitHub Code
Feel free to explore the code and results in more detail here.
Further Reading/Resources
Marco Tulio Ribeiro, Sameer Singh and Carlos Guestrin. Local Interpretable Model-Agnostic Explanations (LIME): An Introduction
Ribeiro, Marco Tulio, et al. ""Why should I trust you?" Explaining the predictions of any classifier." Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 2016.
Gohel, Prashant, Priyanka Singh, and Manoranjan Mohanty. "Explainable AI: current status and future directions." arXiv preprint arXiv:2107.07045 (2021).
Došilović, Filip Karlo, et al. "Explainable artificial intelligence: A survey." 2018 41st International convention on information and communication technology, electronics and microelectronics (MIPRO). IEEE, 2018.
Phillips, P. Jonathon, et al. "Four principles of explainable artificial intelligence." Gaithersburg, Maryland (2020): 18.