
Demystifying Supervised Learning
Understanding its Algorithms, Categories, and Components


Introduction
Welcome back to PureAI! I initially planned to present you with an all-encompassing post on Supervised Learning this week. However, the subject is so rich and extensive that I realized it wouldn't do it justice to squeeze everything into a single article. Therefore, I've decided to break it up into two comprehensive posts over the next two weeks. This week, we'll explore the basics, types, and some popular algorithms used in Supervised Learning. Next week, we'll dive deeper into model evaluation techniques, practical applications, pros and cons, real-world case studies, and future trends. Thank you for joining us on this educational journey!
If you missed last week's post covering the general topic of machine learning and its three pillars, you can find it linked below.

What is Supervised Learning?
Supervised Learning is a subfield of Machine Learning where the model is trained on a labeled dataset. The model makes predictions or decisions based on input data and is corrected when its predictions are incorrect.
Why is it Important?
Supervised Learning forms the backbone of many machine learning applications today, from email filtering and fraud detection to more advanced applications like natural language processing and computer vision.
What Types of Problems Does it Solve?
Supervised Learning is versatile and can be applied to various types of problems, including but not limited to:
Classification: Categorizing items into different classes.
Regression: Predicting numerical values based on input features.
Objective of This Week's Post
In today's post, we'll delve into the foundational concepts, explain the different types of problems that Supervised Learning can solve, and introduce you to some of the key algorithms used in this domain. Let’s jump into the exciting exploration of Supervised Learning!
Basic Concepts
Before diving into the algorithms and types of problems that supervised learning can solve, it's essential to grasp some fundamental concepts. These core elements provide the foundation for understanding how supervised learning works.
Labels and Features
In supervised learning, every data point consists of a set of features and a label. The features are the attributes or variables that describe the characteristics of the item you are trying to make predictions about. For example, in a house price prediction model, features might include the size of the house, the number of bedrooms, the location, and the age of the house.
The label is the "answer" or the outcome that the model aims to predict. Continuing with the house price prediction example, the label could be the price of the house.
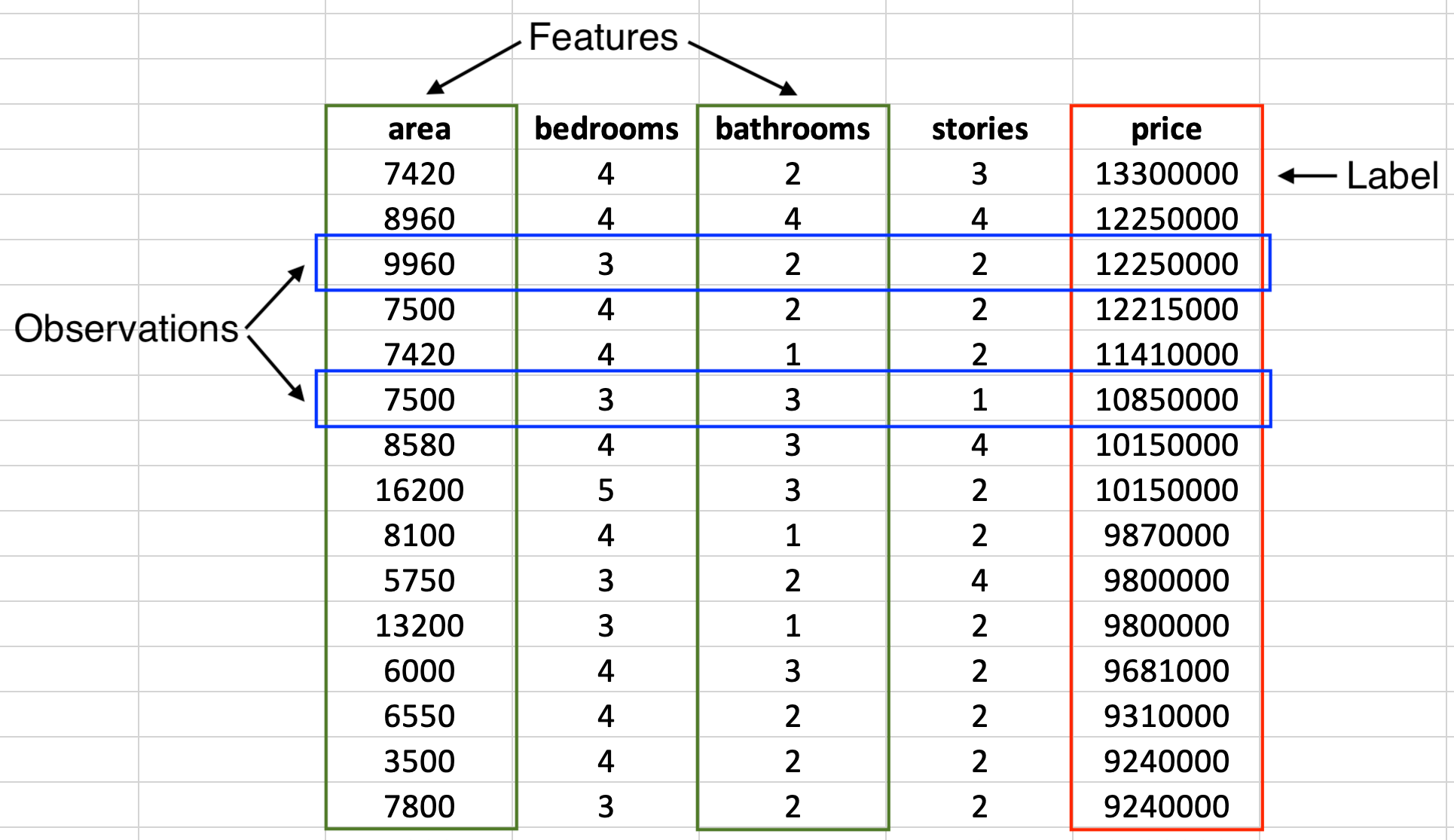
Training Data and Test Data
For a supervised learning model to make accurate predictions, it needs to be trained on a dataset, known as the training data. This dataset consists of numerous examples with both features and their corresponding labels. The model learns to map the features to labels through the training process. High-quality, representative data is crucial for the success of the model; if the data is poor or misleading, the resulting model will also perform poorly or inaccurately. Essentially, data is the backbone of machine learning, underpinning the model's ability to make accurate predictions.
After training, the model's performance needs to be evaluated on a separate dataset, known as the test data. Unlike in the training data, the model has never seen the test data during its learning process, making it a good measure of how well the model can generalize to new, unseen data.
Target Variable
The target variable is another term for the label we want to predict. For classification problems, the target variable is categorical (e.g., "yes" or "no", "spam" or "not spam"). In regression problems, the target variable is numerical (e.g., the price of a house).
The Supervised Learning Algorithm
A supervised learning algorithm is the underlying method used to build the predictive model. It takes the features and labels from the training data and creates a function that can map new, unseen features to labels. The choice of algorithm can depend on the type of problem you're solving (classification vs. regression), the nature of your data, and other factors.
The algorithm iteratively adjusts its internal parameters based on the error of its predictions on the training data, aiming to minimize this error. Once trained, you can input features into this function to get the predicted labels, either for evaluation on the test data or for making predictions on entirely new data.
Types of Supervised Learning Problems
Supervised learning can broadly be categorized into two main types of problems: Classification and Regression. While both involve using input features to make predictions, they differ in the type of output or target variable involved. Let's delve deeper into each type to understand them better.
Classification
In classification problems, the target variable is a category or a label. The algorithm predicts which category a new observation belongs to based on the features provided. Classification can further be broken down into:
Binary Classification
In binary classification, there are only two possible outcomes or classes. The classic example is email spam filtering, where an email is classified either as "Spam" or "Not Spam."
Multi-class Classification
In multi-class classification, there are more than two classes involved. A popular example is handwritten digit recognition, where the target variable can be any digit from 0 to 9.
Regression
Unlike classification, where the output is a category, in regression problems the output is a continuous value. The goal is to predict a quantity based on one or more features. For example, you might use features like square footage, number of bedrooms, and location to predict the price of a house.
Examples of Regression Problems
Stock Price Prediction: Using historical data to predict future stock prices.
Temperature Forecast: Using meteorological data to predict future temperatures.
Hybrid Problems
While the majority of supervised learning problems fall into either classification or regression, there are some hybrid problems that involve elements of both. For instance, a recommendation system may utilize classification to identify types of user behavior but employ regression algorithms to predict the rating a user would give to a particular item.
By understanding the type of problem you are dealing with, you can choose the most appropriate supervised learning algorithm to use. Whether you are categorizing emails as spam or predicting future stock prices, supervised learning provides a framework for solving such diverse problems.
Algorithms Used in Supervised Learning
Supervised learning is a vast field with a plethora of algorithms at its disposal. Each algorithm has its unique strengths, weaknesses, and applications. Let's delve into some of the most commonly used algorithms in supervised learning.
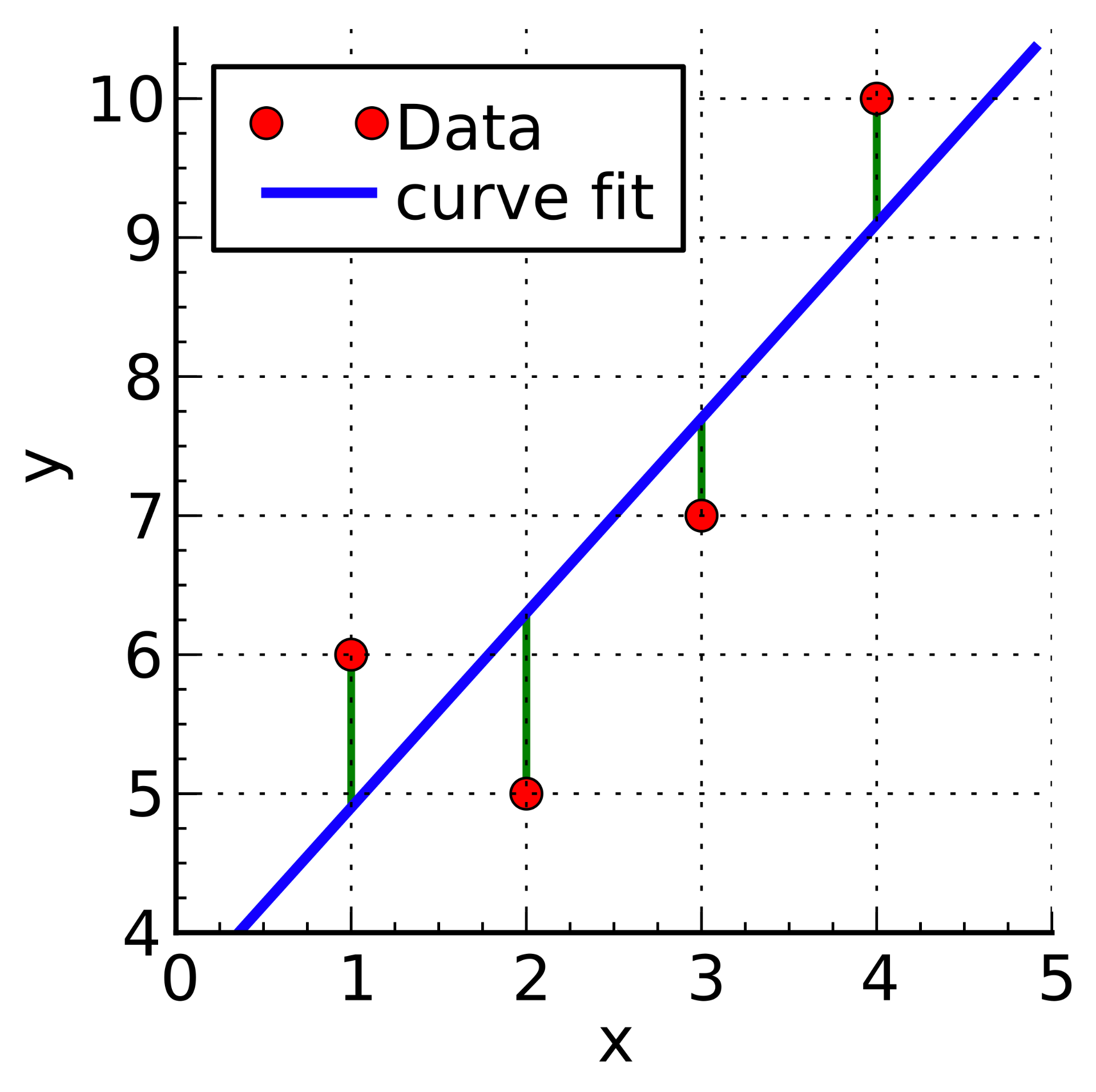
Linear Regression
Overview: Linear Regression is perhaps one of the simplest and most well-known algorithms used for regression tasks. It aims to model the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data.
Use-cases: Predicting house prices, stock prices, and other continuous numerical values.
Strengths and Weaknesses: Easy to implement and interpret but may perform poorly on complex data distributions.
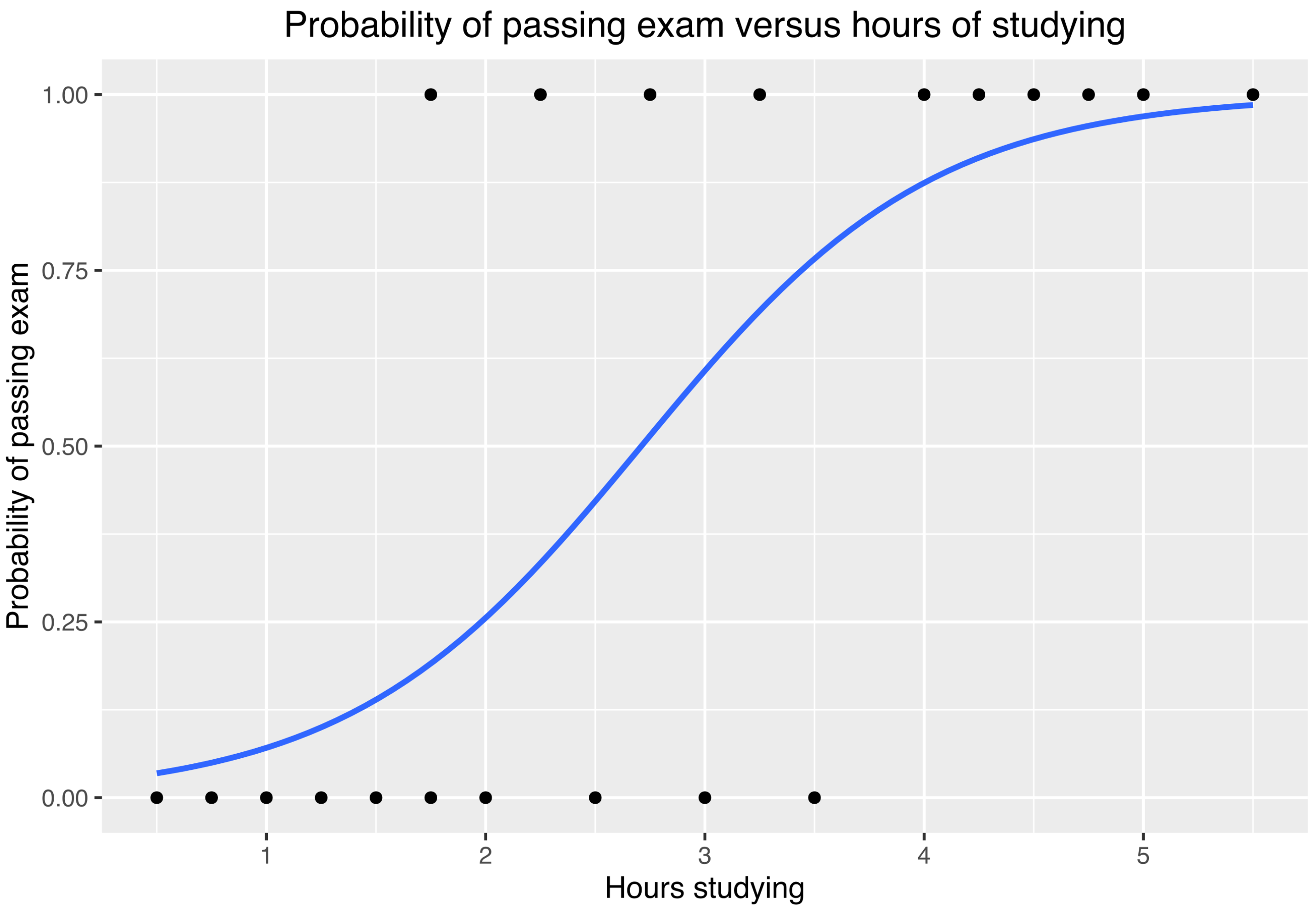
Logistic Regression
Overview: Despite its name, Logistic Regression is used for binary classification problems. It estimates the probability that a given input belongs to a certain category.
Use-cases: Email spam filtering, customer churn prediction.
Strengths and Weaknesses: Highly interpretable, but like Linear Regression, it may struggle with complex relationships.
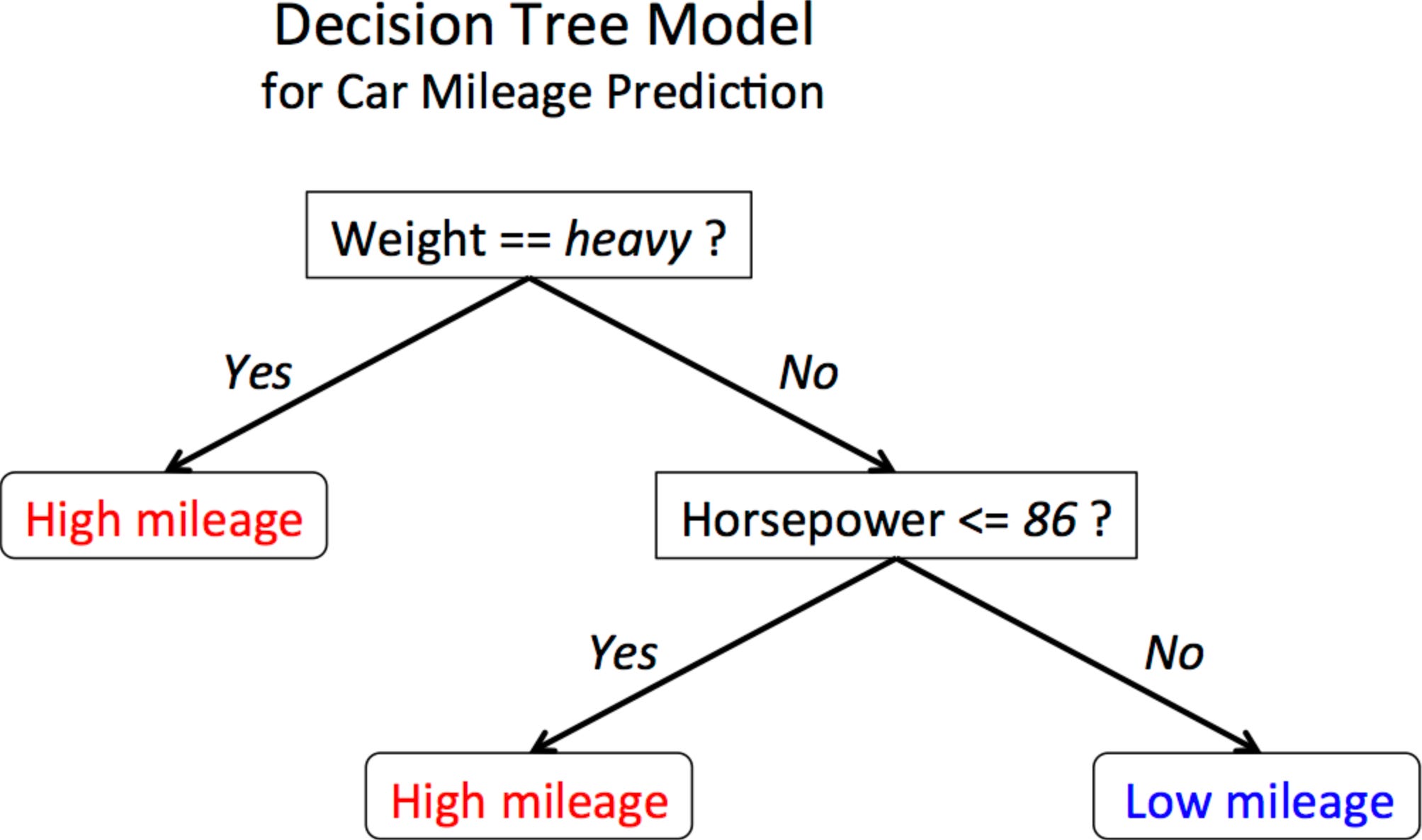
Decision Trees
Overview: Decision Trees split the data into two or more homogeneous sets based on the most significant attribute(s) at each level, making decisions at every node.
Use-cases: Medical diagnosis, credit risk assessment.
Strengths and Weaknesses: Easy to visualize and interpret but prone to overfitting.
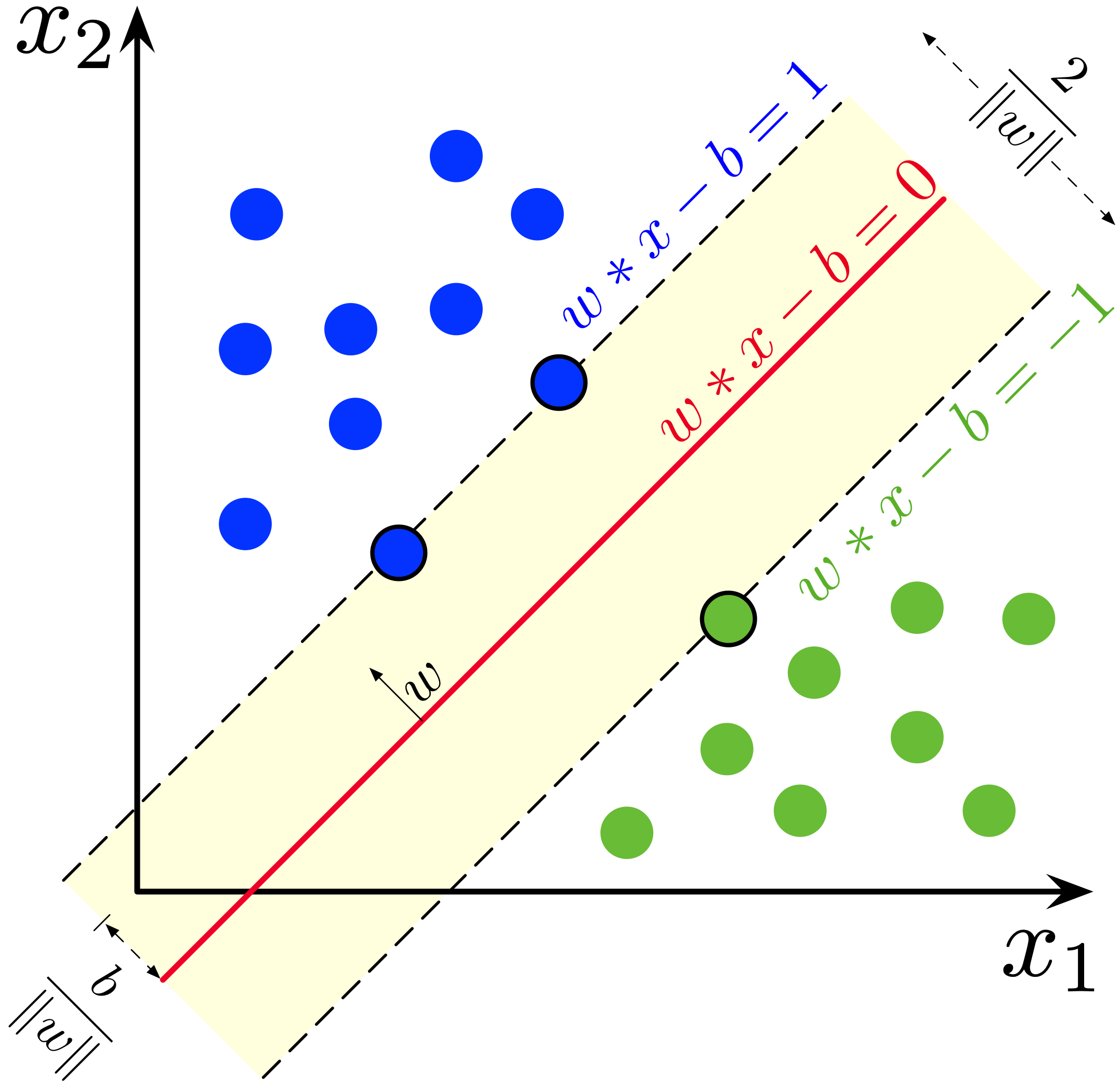
Support Vector Machines (SVM)
Overview: SVM finds the hyperplane that best separates a dataset into classes. It is effective in high-dimensional spaces.
Use-cases: Text classification, image recognition.
Strengths and Weaknesses: Effective in high dimensions but can be sensitive to noise.
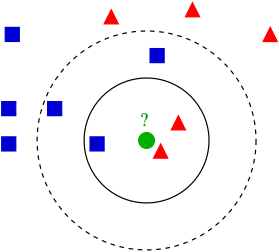
k-Nearest Neighbors (k-NN)
Overview: k-NN classifies a data point based on how its neighbors are classified.
Use-cases: Recommender systems, handwriting detection.
Strengths and Weaknesses: Simple and effective but computationally expensive.
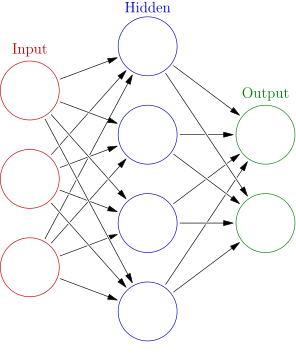
Neural Networks
Overview: A neural network consists of layers of interconnected nodes and is used for both classification and regression tasks. It is particularly useful for capturing complex data relationships.
Use-cases: Natural language processing, computer vision.
Strengths and Weaknesses: Highly flexible but can be computationally intensive and requires a lot of data.
Random Forests
Overview: A Random Forest is an ensemble of Decision Trees, generally trained with the "bagging" method. This ensemble method aims to improve the overall performance and robustness of the model.
Use-cases: Fraud detection, customer segmentation.
Strengths and Weaknesses: Reduces overfitting seen in Decision Trees but can be complex and time-consuming to train.
Ensemble Methods
Overview: Apart from Random Forests, there are other ensemble methods like Gradient Boosting that combine multiple algorithms to achieve better predictive performance.
Use-cases: Anywhere individual algorithms are used but require improved accuracy.
Strengths and Weaknesses: Usually more accurate but can be computationally expensive.
This section aims to give you an understanding of the various algorithms utilized in supervised learning. Each algorithm has its merits and limitations, and the choice of algorithm often depends on the specific requirements of a project.
Conclusion
In this week's post, we've laid the groundwork for understanding supervised learning, a core technique in the realm of machine learning. We delved into its basic concepts, discussing essential terms like labels, features, training data, and test data. We also examined the types of problems that supervised learning can solve, including classification and regression.
Moreover, we explored a range of algorithms commonly used in supervised learning, such as Linear Regression, Decision Trees, Support Vector Machines, k-Nearest Neighbors, and Neural Networks. Each of these algorithms offers unique advantages depending on the problem you're trying to solve.
While we've covered a lot of ground, this is just the tip of the iceberg. Next week, we'll be diving deeper into the world of supervised learning. We'll look at how to evaluate the models you've built, and explore real-world applications. You'll also get a glimpse of the future trends shaping this fascinating field.
Stay tuned for next week’s post where we'll continue our journey into the captivating world of supervised learning. Until then, feel free to explore some of the algorithms we've discussed today further, and get your hands dirty with some real-world data!
References:
Russell, S. J. and Norvig, P., Artificial Intelligence: A Modern Approach, 4th Edition, Prentice Hall, 2021